


Vesti
U ovoj sekciji biće objavljivane najsvežije vesti našeg projektnog tima.

Intervju za Radio Beograd 202
14.5.2026.
Naš rukovodilac, dr Dražen Drašković, učestvovao je 12. maja 2026. godine u emisiji "Pravac 202". Tema emisije bila je "Svađa sa neživim stvarima", a voditeljke emisije Jelena Knežević i Kruna Pintarić razgovarale su sa Draženom o tome kako bolje da upotrebljavamo modele veštačke inteligencije umesto što se ljutimo na njih, i kako nam veštačka inteligencija pomaže da digitalno okruženje ne bude preteće i nesigurno mesto. U emisiji je predstavljen softver STOP za sprečavanje digitalnog nasilja kod mladih u Srbiji. Emisiju možete poslušati na sledećem LINKU.


Build with AI 2026 konferencija & hakaton
31.3.2026.
Na hakatonu „Build with AI 2026“, koji je održan prošlog vikenda (od 27. do 29. marta 2026. godine) u Palati nauke - Zadužbini Miodraga Kostića, u organizaciji Google Developer Group Belgrade i ETF-a u Beogradu, okupili su se programeri, inovatori i tehnološki entuzijasti kako bi sarađivali i kreirali napredna AI rešenja. Na konferenciji su održana tri predavanja na teme:
- AI Agents Face-Off: Same App, Multiple frameworks (predavač: Elaine Dias Batista)
- Way Back Home Series - Mission I: Identify Yourself (predavač: Konstantinos Kechagias)
- VLM System Design for an AI Assistant (predavač: Darya Vinogradova)


Nakon konferencije, organizovan je 36-časovni hakaton u kome je učestvovalo 10 timova od 3 do 4 studenta. Članovi našeg tima su takođe učestvovali u ovom događaju kao mentori i sudije, pružajući podršku učesnicima i deleći svoje stručno znanje.




Intervju za emisiju "Naučni portal" na TV RTS 1
20.3.2026.
Članica našeg istraživačkog tima, dr Jelica Cincović, učestovala je u emisiji „Naučni portal“, kako bi prezentovala projekat i dobijene rezultate. Tokom intervju, Jelica je otkrila šta se to krije ispod softvera za detekciju govora mržnje na srpskom jeziku, zašto je taj softverski alat značajan i gde se može primeniti u praksi. Kompletnu epizodu ove emisije možete pogledati OVDE.

DEV FEST 2025
1.12.2025.
Dev Fest 2025, hakaton i konferencija je trodnevni inovativni tehnološki događaj, koji je održan od 28. do 30. novembra 2025. u Palati nauke - Zadužbini Miodraga Kostića. Manifestaciju su organizovali Google Developer Group on Campus - University of Belgrade, i Laboratorija za analizu podataka i primenjenu veštačku inteligenciju Elektrotehničkog fakulteta Univerziteta u Beogradu (University of Belgrade, School of Electrical Engineering).


Učestvovalo je 10 timova i 39 takmičara, koji su tokom intenzivnog rada razvijali kreativna i tehnički zahtevna rešenja u oblasti primene veštačke inteligencije u mobilnim aplikacijama. Nakon finalnih prezentacija, žiri je proglasio pobednika: tim Tech Turtles i projekat „Tempi”.
Ovo takmičenje je podržano od strane projektnog tima nacionalnog istraživačkog projekta STOP (#11113), finansiranog kod Fonda za nauku Republike Srbije, sa ciljem šire primene veštačke inteligencije i velikih jezičkih modela u softverskom razvoju.



Učešće na konferenciji "IEEE ERK 2025" u Portorožu
1.10.2025.
Naši istraživači sa Elektrotehničkog fakulteta Univerziteta u Beogradu prezentovali su naše projektne naučne rezultate u oblasti obrade prirodnog jezika i automatske detekcije govora mržnje na srpskom jeziku u okviru 34. internacionalne konferencije elektrotehnike i računarstva ERK, u Portorožu, Slovenija.


Projekat STOP je prezentovan kroz 3 naučna rada:
- Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian
- LLM-Driven Hate Speech Detection in News Content Extracted from URLs
- From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs

Vikend pun inovacija: Uspešno održan „Build with AI“ hakaton!
05.05.2025.
📢 „Build with AI“, inovativni hakaton, održan je ovog vikenda (3–4. maja 2025) u Palati nauke,
u organizaciji Google Developer grupe Univerziteta u Beogradu i Laboratorije za analizu podataka
i primenjenu veštačku inteligenciju Elektrotehničkog fakulteta.
Učestvovalo je 10 timova, a nakon 36 sati rada, 9 ih je uspešno prezentovalo projekte.
Žiri je imao težak zadatak, ali su nagrađeni:
🥇 Vibe Coders (projekat „Safe Space“)
🥈 Charmander (projekat „Better Search“)
🥉 (deljeno): Debug Divas (projekat „Lumi“) i VTŠ AppsTeam (projekat „Hate Guard“)
Čestitamo svim timovima na kreativnosti i posvećenosti!
Posebnu zahvalnost dugujemo Gerardu Sansu, dr Draženu Draškoviću i Vanji Milutinović,
koji su održali predavanja i bili članovi žirija, zajedno sa članovima našeg STOP tima,
dr Vladimirom Jocovićem i Jelicom Cincović.

Poseta centru za primenu veštačke inteligencije u okviru Palate nauke
17.01.2025.
📢 Danas smo svoj redovni mesečni sastanak održali u našoj novoj istraživačkoj laboratoriji za primenjenu veštačku inteligenciju u prelepoj Palati nauke - Zadužbini Miodraga Kostića u Beogradu. Na našem sastanku smo pretprocesirali nekonzistentne labelirane podatke i pripremali ih za nove aktivnosti na projektu i narednu fazu izrade prvih modela. Takođe, dogovorili smo pisanje novih naučnih publikacijama u ovom projektnom kvartalu. Na kraju dana obišli smo stalnu izložbenu postavku u Palati nauke, i družili se sa đacima predškolskih ustanova, kako bi im otvorili čarobna vrata nauke. Radujemo se godini pred nama u novim prostorijama, sa novim izazovima u projektu, i želimo svim pratiocima mnogo sreće i uspeha.

Intervju za Studio znanja - RTS2
07.12.2024.
📢 Članica našeg tima, Jelica Cincović, nedavno je predstavila STOP projekat u emisiji "Studio znanja". Tema emisije je bila: Veštačka inteligencija u obrazovanju. Video možete pogledati OVDE.

Učešće na CEISEE 2024
03.10.2024.
Dvadeseti Kina-Evropa internacionalni simpozijum o obrazovanju u softverskom inženjerstvu održao se 02. i 03.10. u Beogradu. Prvi dan simpozijuma održan je na Elektrotehničkom fakultetu, Univerziteta u Beogradu, a drugi dan u Palati Srbije. Članovi našeg tima prezentovali su svoje radove i kroz bogatu razmenu znanja sa kolegama iz Kine, spremni smo da se uputimo u nove naučne pustolovine. Ova kolaboracija pospešuje kreativnost u utemeljuje put budućim inovativnim projektima.




Intervju za TV NOVA
15.7.2024.
Naš rukovodilac projekta, dr Dražen Drašković, gostovao je u jutarnjem programu "Probudi se" na TV NOVA, gde je govorio o ovogodišnjem upisu srednjoškolaca na Elektrotehnički fakultet u Beogradu, uticaju veštačke inteligencije na informacione tehnologije, kao i projektu STOP, koji finansira Fond za nauku Repubulike Srbije, u kome razvijamo softverski sistem za otkrivanje govora mržnje na srpskom jeziku. On je istakao da je na smanjenje broja prijavljenih za IT odeljenja na univerzitetima najviše uticala depopulacija i više od 4 hiljade maturanata manje. Prilog možete pogledati OVDE.
Redovni mesečni sastanak projektnog tima
2.7.2024.
📢 Tim projekta STOP održao je redovni mesečni sastanak, u sali za sastanke Elektrotehničkog fakulteta 🏫 Na sastanku je urađena analiza dosadašnjeg rada i napisan je polugodišnji izveštaj, koji je predat Fondu za nauku. Tim je konstatovao da su sve planirane aktivnosti uspešno izvršene i da su ostvareni svi traženi rezultati. Tokom leta očekuje nas sređivanje baze kratkih tekstova na srpskom jeziku i labeliranje podataka, kao i završetak preglednog naučnog rada, koji pripremamo za objavljivanje u internacionalnom časopisu. Pratite naše aktivnosti i dalje!


Učešće na panelu XIX međunarodnog simpozijuma SymOrg 2024
15.6.2024.
U subotu, 15. juna 2024. godine u okviru XIX međunarodnog simpozijuma SymOrg 2024, organizovan je pane (okrugli sto), u organizaciji Fakulteta organizacionih nauka. Tema panela bila je "Synergy of Humans and Technology in Higher Education", a učešće u panelu među dekanima i predstavnicima fakulteta iz celog regiona, uzeo je Dr Dražen Drašković, rukovodilac našeg projekta STOP. Dr Drašković je govorio o izvanrednoj saradnji Elektrotehničkog fakulteta i Fakulteta organizacionih nauka u Beogradu na zajedničkim master studijama iz digitalne transformacije, izazovima koji su nastupili u nastavi uvođenjem alata veštačke inteligencije i tokom pandemije korona virusa, a istakao je i nove softverske sisteme koje razvijamo u okviru Laboratorije za analizu podataka i primenu veštačke inteligencije, među kojima i alat iz projekta STOP.


Učešće na međunarodnoj konferenciji IcETRAN 2024
7.6.2024.
STOP tim je učestvovao na Međunarodnoj konferenciji IcETRAN, održanoj u Nišu, od 3. do 6. juna, u organizaciji Društva za ETRAN i Elektronskog fakulteta u Nišu. Članovi našeg tima prezentovali su rad o primeni velikih jezičkih modela i učestvovali u radu ove tradicionalne konferencije.

Intervju za K1 televiziju
28.5.2024.
Naš rukovodilac projekta, dr Dražen Drašković, govorio je u jutarnjem programu "Uranak" na televizijskoj stanici K1, o projektu STOP koji se razvija u laboratoriji za analizu podataka i primenu veštačke inteligencije Elektrotehničkog fakulteta u Beogradu. Prilog možete pogledati OVDE.

Učešće na trećoj srpskoj međunarodnoj konferenciji o primenama veštačke inteligencije
25.5.2024.
STOP tim je učestvovao na Trećoj srpskoj međunarodnoj konferenciji o primenjenoj veštačkoj inteligenciji održanoj u Kragujevcu 23. i 24. maja. Članovi našeg tima Dražen Drašković i Jelica Cincović održali su prezentacije o temama otkrivanja govora mržnje na srpskom jeziku, tehnikama analize podataka i otkrivanju propagande na srpskom jeziku. Naš rad pod nazivom Primena veštačke inteligencije u otkrivanju govora mržnje na srpskom jeziku dobio je nagradu za najbolji studentski rad na konferenciji.

Čestitke našem članu tima Urošu Radenkoviću na odbranjenom doktoratu
24.5.2024.
U sredu 22. maja 2024. godine, član našeg projektnog STOP tima, Uroš Radenković, sa uspehom je odbranio svoju doktorsku disertaciju pod naslovom "Spekulativno izvršavanje instrukcija sa neprecizno predviđenim operandima". Čestitamo Urošu na ostvarenom zvanju doktora nauka elektrotehnike i računarstva, i želimo mu mnogo uspeha u daljem naučnom radu!

Čestitke našem članu tima Dr Vladimiru Jocoviću na ostvarenoj nagradi za najbolji doktorat iz računarstva
15.5.2024.
U sredu 15. maja 2024. godine, članu našeg projektnog STOP tima, dr Vladimir Jocović, uručena je nagrada za najbolji doktorat iz oblati informatike za 2023. godinu. Vladimir je dobio nagradu za svoju doktorsku disertaciju odbranjenu u decembru 2023. godine na Elektrotehničkom fakultetu Univerziteta u Beogradu, pod naslovom „Automatizovano ocenjivanje papirnih testova korišćenjem tehnika veštačke inteligencije“, a pod mentorstvom prof. dr Boška Nikolića i doc. dr Saše Stojanovića. Nagradu dodeljuje Matematički institut Srpske akademije nauka i umetnosti (MI-SANU).
Napravljen korpus ružnih i pogrdnih reči u srpskom jeziku
15.4.2024.
U toku februara i marta, naš projektni STOP tim je radio na prikupljanju i razvoju korpusa ružnih i pogrdnih reči u srpskom jeziku (rezultat D2.1. projektnog plana). Reči su prikupljanje iz različitih izvora, sa veb sajtova i portala, iz digitalnih i štampanih rečnika srpskog jezika, koji su zatim skenirani i gde su korišćene tehnike optičkog prepoznavanja karaktera, kao i manuelnog labeliranja podataka. Rezultati su prikazani u sekciji Resursi.
Učešće na AI konferenciji istraživača iz Srbije i Kine
12.4.2024.
Naš tim učestvovao je juče na konferenciji posvećenoj razvoju veštačke inteligencije u organizaciji Fonda za nauku Republike Srbije i Nacionalne fondacije za prirodne nauke Republike Kine. Konferencija je imala za cilj upoznavanje istraživača iz dve zemlje i predstavljanje dosadašnjih projekata u ovoj oblasti. Zahvaljujemo se Fondu za nauku što smo bili deo ovog interesantnog naučnog događaja.
Drugi zvaničan sastanak pregleda projekta
3.4.2024.
📢 Tim projekta STOP sastao se danas, u sali za sastanke Elektrotehničkog fakulteta 🏫 Na sastanku su podeljeni zadaci za predstojeće tromesečje 📝 Vredno radimo na prvom softveru za otkrivanje govora mržnje na srpskom jeziku i radujemo se novim izazovima koji su pred nama!


Svečana ceremonija promocije dobijenih projekata iz ciklusa "Program mladih istraživača - PROMIS 2023"
20.3.2024.
U sredu 20. marta 2024. godine održana je proslava povodom pet godina postojanja Fonda za nauku Republike Srbije. Tokom proslave, prisutnima su se obratili v.d. direktora Fonda za nauku g-đa dr Milica Đurić-Jovičić, Ministarka nauke, tehnološkog razvoja i inovacija, g-đa dr Jelena Begović, kao i predstavnici Evropske unije i Svetske banke. Na proslavi su posebno istaknuti rukovodioci odobrenih projekata iz poziva Promis 2023, i projekti koji su nagrađeni i koji su dobili dvogodišnje finansiranje kod Fonda za nauku Republike Srbije.

Panel o sajber bezbednost trendovima i izazovima
15.3.2024.
U okviru jubilarne 30. nacionalne naučno-stručne konferencije "YU INFO", naš tim je organizovao specijalni događaj - stručni panel, na temu "Sajber bezbednost trendovi i izazovi u zaštiti velikih sistema", u utorak, 12. marta 2024. godine u kongresnoj sali "Pančić A" u hotelu "Grand" na Kopaoniku.
Panel je moderirao i osmislio rukovodilac našeg projekta "STOP", prof. dr Dražen Drašković, a učešće su uzeli: prof. dr Slavko Gajin (Matematički fakultet u Beogradu), doc. dr Maja Vukasović (Elektrotehnički fakultet u Beogradu), master pravnih nauka Bojana Marinković (University Newcastle, UK) i dipl. inž. Marko Džida (Serbia And Montenegro Air Traffic Services Smatsa Llc).
Sajber pretnje u prethodnih nekoliko godina postale su sve veće po organizacije i njihove velike sisteme, a korisnički podaci veoma često nađu se na udaru zlonamernih korisnika (hakera). U poslednjih godinu dana padali su mnogi veliki softverski sistemi u Srbiji i regionu. Na panelu se diskutovalo o efikasnim bezbedonosnim merama, regulatornim zahtevima (kao što su GDPR i HIPAA), dobrim praksama u organizacijama u Srbiji i svetu, granicama između primene robusnih bezbedonosnih mera i održavanja sistema, koji su to podaci opasni da se zloupotrebe, i mnogim drugim pitanjima. Panel je privukao veći broj zainteresovanih učesnika konferencije, sa interesantnim pitanjima, pa je disusija panela bila vrlo plodotvorna i korisna.


Uspešno učešće naših istraživača na konferencijama "YU INFO 2024" i "ICIST 2024"
12.3.2024.
Od 10. do 13. marta 2024. na Kopaoniku je održana jubilarna 30. IKT konferencija "YU INFO 2024" i 14. internacionalna konferencija "ICIST 2024", na kojima je učešće uzelo više od 350 učesnika iz Srbije i sveta. Obe ovogodišnje konferencije bile su najviše u znaku veštačke inteligencije, obrade velikih podataka i velikih jezičkih modela. Na konferencijama je prezentovano 73 rada u sedam sesija na nacionalnom nivou, i 92 rada na internacionalnom nivou. Program konferencija dostupan je na sledećem linku.
U ponedeljak, 10. marta 2024., u naučnoj sesiji "Pre-trained Large Language Models" u okviru internacionalne konferencije "ICIST 2024" naš tim je prezentovao rad pod naslovom "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", a u utorak, 11. marta, u naučnoj sesiji "Veštačka inteligencija i mašinsko učenje" u okviru nacionalne konferencije "YU INFO 2024", prezentovan je rad pod naslovom "Otkrivanje govora mržnje vođeno veštačkom inteligencijom". Oba naučna rada nastala su kao rezultat našeg projekta u prva dva meseca našeg istraživanja.

Prvi sastanak projektnog tima
10.1.2024.
U prostorijama Elektrotehničkog fakulteta, tim projekta STOP održao je inicijalni sastanak u sredu, 10. januara 2024. godine. Rukovodilac projekta podelio je zadatke članovima za prvih mesec dana projekta i prikazao pregled polugodišnjih ciljeva.


Informacije o projektu
Akronim: STOP
Rezultat saradnje istraživača biće novi softverski sistem koji će detektovati govor mržnje na srpskom jeziku i koji će biti od velikog značaja u sprečavanju digitalnog nasilja u Srbiji.
Period: jan. 2024 - dec. 2025 | Budžet: 140,000.00 €
Problem istraživanja kojim se bavi ovaj projekat je otkrivanje govora mržnje u tekstovima na srpskom jeziku na internetu. Otkrivanje i smanjenje govora mržnje je ključno za bezbednost i dobrobit pojedinaca, jer inače može dovesti do štete i tragedija u stvarnom svetu. Tradicionalne metode ručnog praćenja sadržaja na mreži oduzimaju mnogo vremena, skupe su i neefikasne u radu sa ogromnom količinom sadržaja koji generiše korisnik. Stoga postoji potreba za automatizovanim alatima koji mogu efikasno otkriti i sprečiti govor mržnje, koji čine primarne ciljeve ovog projekta. Ovaj projekat takođe predstavlja značajnu prekretnicu kao prva inicijativa za razvoj modela detekcije govora mržnje dizajniranih isključivo za srpski jezik.
Uticaj ovog projekta je izuzetan. Softver štiti pojedince od onlajn zlostavljanja i nasilja otkrivanjem i sprečavanjem govora mržnje. Rezultati istraživanja projekta, uključujući razvijeni skup podataka, NLP modele i softverski sistem, mogu unaprediti oblast detekcije govora mržnje na srpskom jeziku i uticati na različite sektore, uključujući zdravstvo, obrazovanje, nauku i industriju.
-
Institucije koje učestvuju na projektu:
- Univerzitet u Beogradu - Elektrotehnički fakultet (ETF)




Članovi tima
Tim čine istraživači sa Elektrotehničkog fakulteta Univerziteta u Beogradu

Prof. dr Dražen Drašković
Rukovodilac projekta
Doc. dr Vladimir Jocović
Član projektnog tima
Marko Mićović, master inž. el. i rač.
Član projektnog tima
As. dr Uroš Radenković
Član projektnog tima
Jelica Cincović, master inž. el. i rač.
Član projektnog tima
Adrian Milaković, master inž. el. i rač.
Član projektnog timaResursi
Ovde će biti prikazani resursi koji će biti objavljeni tokom trajanja projekta.
Resurs D2.1. - Korpus ružnih i pogrdnih reči u srpskom jeziku
objavljen 4.4.2024.
Ovaj rezultat sadrži:
- Rečnik pogrdnih naziva po kategorijama (D2.1a)
- Rečnik narodnih pogrdnih izraza (D2.1b)
Resurs D2.a. - Veb ekstenzija za uklanjanje ružnih i pogrdnih reči u srpskom jeziku
objavljen 16.10.2024.
Ovaj rezultat sadrži:
- Veb ekstenziju za veb pregledač Google Chrome
Objavljeni radovi
U ovoj sekciji biće objavljivani radovi sa konferencija i iz naučnih časopisa. ( Pristupna lozinka: StopETF! )
-
D.Drašković et al., "Otkrivanje govora mržnje vođeno veštačkom inteligencijom"
D.Drašković, V.Jocović, A.Milaković, M.Mićović, U.Radenković, J.Cincović, "Otkrivanje govora mržnje vođeno veštačkom inteligencijom", Zbornik radova 30. IKT konferencije "YU INFO 2024", Informaciono društvo Srbije, pp. 182-186, Kopaonik, Serbia, March 2024 [ISBN: 978-86-85525-31-5]
Link: Pogledaj rad u Zborniku |
Apstrakt: Govor mržnje predstavlja sve što vređa pojedinca, populaciju ili pojavu na bilo kojoj osnovi, što može da bude seksualna orijentacija, pripadnost nekoj religiji, nacionalnost, rasa, pripadnost određenoj grupi, izrečeni neki stavovi ili slično. Otkrivanje i smanjenje govora mržnje je ključno za bezbednost i dobrobit pojedinaca, jer inače takav govor može dovesti do štete i tragedija u stvarnom svetu. Tradicionalne metode manuelnog praćenja sadržaja na internetu oduzimaju mnogo vremena, skupe su i neefikasne u radu sa ogromnom količinom korisničkog sadržaja. Zato postoji potreba za razvojem automatizovanih alata koji mogu efikasno otkriti ili sprečiti objavljivanje govora mržnje, i koji čine primarne ciljeve ovog istraživanja. Ovo istraživanje predstavlja značajnu prekretnicu kao prva inicijativa za razvoj modela detekcije govora mržnje dizajniranog za srpski jezik. U ovom radu data je analiza postojećih tehnika koje otkrivaju i klasifikuju govor mržnje u drugim jezicima, a dat je i predlog modela, koji će biti razvijan za detekciju i klasifikaciju govora mržnje na srpskom jeziku. Istraživanje se sprovodi u okviru nacionalnog projekta „Softver za prevenciju tekstualnih uvreda na srpskom jeziku: Otkrivanje govora mržnje pomoću veštačke inteligencije“, finansiranog od strane Fonda za nauku Republike Srbije u periodu 2024-2025. -
M.Dodović et al., "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation"
M.Dodović, M.Ogrizović, D.Miladinović, D.Drašković, "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", Springer's Lecture Notes in Networks and Systems, with title Disruptive Information Technologies for a Smart Society, vol 860, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-031-71419-1_30]
Link: Pogledaj rad u Zborniku |
Apstrakt: Sentiment analysis, a pivotal aspect of NLP (Natural Language Processing), of-fers profound insights into the public sentiment from vast swathes of unstruc-tured textual data. This paper presents an empirical investigation into the applica-bility and effectiveness of the BERT (Bidirectional Encoder Representations from Transformers) algorithm for sentiment analysis, particularly focused on product reviews. The research delves into the nuances of consumer language expressions and evaluates the capacity of BERT to accurately classify sentiment in a large-scale dataset of food product reviews. The results achieved through this research are significant, with the fine-tuned BERT model demonstrating high accuracies, indicating its robustness and suitability for the sentiment classification task. In addressing the challenges posed by the varying lengths of consumer reviews, this study offers a methodological analysis for selecting the optimal max_seq_length parameter within BERT’s framework. A critical balance is achieved between computational efficiency and the comprehensive inclusion of informative content within the reviews. Furthermore, the paper confronts the prevalent issue of class imbalance in sentiment analysis datasets by employing a weighted loss function during the training of BERT. This technique ensures equi-table representation and consideration of all sentiment classes, enhancing the model's accuracy and fairness. -
J.Cincović et al., "Applied Artificial Intelligence in Detection Hate Speech"
J.Cincović, U.Radenković, M.Mićović, A.Milaković, V.Jocović, D.Drašković, "Applied Artificial Intelligence in Detection Hate Speech", in publication Applied Artificial Intelligence 4: Medicine, Biology, Chemistry, Financial, Games, Engineering AAI 2024 - Lecture Notes in Networks and Systems, vol 1446, Springer, Cham, Kragujevac, May 2024 [DOI: https://doi.org/10.1007/978-3-031-99201-8_11]
Link: Pogledaj rad u Zborniku |
Apstrakt: The problem this research addresses is detecting hate speech (HS) in texts in Serbian on the Internet. Detecting and reducing HS is crucial for the safety and well-being of individuals, as it can otherwise lead to real-world harm and tragedies. Traditional methods of manually monitoring online content are time-consuming, costly, and ineffective in dealing with the vast amount of user-generated content. Therefore, there is a need for automated tools that can efficiently detect and prevent HS, which constitutes the primary goal of this research. In this paper, we describe the methods of data collection that we intend to implement, present a short analysis of the existing solutions, and provide the conceptual solution of the model. -
D.Drašković et al., "Data analysis techniques and detection of propaganda in Serbian online media in 2023"
D.Drašković, M.Ogrizović, M.Dodović, M.Obradović, "Data analysis techniques and detection of propaganda in Serbian online media in 2023", in Applied Artificial Intelligence 4: Medicine, Biology, Chemistry, Financial, Games, Engineering, AAI 2024 - Lecture Notes in Networks and Systems, vol 1446, Springer, Cham, Kragujevac, May 2024 [DOI: https://doi.org/10.1007/978-3-031-99201-8_12]
Link: Pogledaj rad u Zborniku |
Apstrakt: Propaganda is a technique by which people manipulate information to direct the behavior of an individual or group, with the aim of provoking a desired reaction. Propaganda is strongly expressed in the spread of religion, political parties, and autocratic governments. In this paper, the most common propaganda techniques are presented, which propaganda implementers can use in shaping and realizing their messages. A certain content of short texts published on the portals of media companies in Serbia was collected. Then, using machine learning techniques, a model was developed, which was trained to classify the text as propaganda or not propaganda. This research included texts that were published on the portals RTS, Politika, B92, Blic, N1, and Danas in 2023. The texts were collected in real-time, because some media portals do not have an archive. -
L.Hrvačević et al., "Development of a web system with an automated question generator based on large language models"
Hrvačević Luka, Cincović Jelica, Milaković Adrian, Jocović Vladimir, Matvejev Valerijan, Drašković Dražen, "Development of a web system with an automated question generator based on large language models," 2024 11th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Niš, Serbia, 2024, pp. 1-6 [DOI: 10.1109/IcETRAN62308.2024.10645106].
Link: Pogledaj rad u Zborniku |
Apstrakt: In this paper, we describe the possibility of using large language models (LLMs) in education through the development of a modern web system. A web-based platform employing LLMs to produce questions and answers spanning diverse domains, drawing upon Serbian Wikipedia as its primary knowledge repository. Leveraging LLMs for question-and-answer generation represents a novel methodology in quiz development. Additionally, incorporating Wikipedia enhances the accuracy and pertinence of the generated questions, thereby enriching the overall user experience. -
J. Tufegdžić et al., "Application of WebAssembly technology in high-performance web applications"
Tufegdžić Janko, Dodović Matija, Ogrizović Mihajlo, Babić Nikola, Đukić Jovan, Drašković Dražen, "Application of WebAssembly technology in high-performance web applications," 2024 11th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Niš, Serbia, 2024, pp. 1-6 [DOI: 10.1109/IcETRAN62308.2024.10645198].
Link: Pogledaj rad u Zborniku |
Apstrakt: This research paper explores the efficacy of WebAssembly technology in enhancing the performance of web applications, with a focus on graphic-intensive domains such as video games, simulations, and image processing. WebAssembly, a binary instruction format designed for browsers, offers performance comparable to desktop applications by executing code within a secure, low-level virtual machine environment. The study further examines the integration of WebAssembly into various programming languages such as C/C++, C#, and Rust, highlighting its cross-platform capabilities and efficient memory management. Through the development of a website that hosts retro-themed video games, the paper assesses performance across different platforms, demonstrating that while unrestricted desktop platforms show higher speeds, regulated environments exhibit negligible performance discrepancies. The findings suggest that while WebAssembly substantially boosts web application performance, opportunities for further enhancements in areas such as garbage collection, debugging, and JavaScript integration remain. This research underscores WebAssembly's potential to revolutionize web application development, providing a robust framework for future advancements in complex web-based applications. -
M.Ogrizović, D.Drašković, D.Bojić, "Quality assurance strategies for machine learning applications in big data analytics: an overview"
Ogrizović, M., Drašković, D., Bojić, D., "Quality assurance strategies for machine learning applications in big data analytics: an overview," Journal of Big Data 11, 156 (2024) [DOI: https://doi.org/10.1186/s40537-024-01028-y]
Link: Pogledaj rad |
Apstrakt: Machine learning (ML) models have gained significant attention in a variety of applications, from computer vision to natural language processing, and are almost always based on big data. There are a growing number of applications and products with built-in machine learning models, and this is the area where software engineering, artificial intelligence and data science meet. The requirement for a system to operate in a real-world environment poses many challenges, such as how to design for wrong predictions the model may make; How to assure safety and security despite possible mistakes; which qualities matter beyond a model’s prediction accuracy; How can we identify and measure important quality requirements, including learning and inference latency, scalability, explainability, fairness, privacy, robustness, and safety. It has become crucial to test thoroughly these models to assess their capabilities and potential errors. Existing software testing methods have been adapted and refined to discover faults in machine learning and deep learning models. This paper covers a taxonomy, a methodologically uniform presentation of all presented solutions to the aforementioned issues, as well as conclusions about possible future development trends. The main contributions of this paper are a classification that closely follows the structure of the ML-pipeline, a precisely defined role of each team member within that pipeline, an overview of trends and challenges in the combination of ML and big data analytics, with uses in the domains of industry and education. -
A.Milaković et al., "Detecting ugly and derogatory words in Serbian language using a web browser extension"
A. Milaković, V. Jocović, J. Cincović, M. Mićović, U. Radenković, D.Drašković, "Detecting ugly and derogatory words in Serbian language using a web browser extension", 2024 32nd Telecommunications Forum (TELFOR), Belgrade, Serbia, November 2024, pp. 1-4 [DOI: https://doi.org/10.1109/TELFOR63250.2024.10819059]
Link: Pogledaj rad |
Apstrakt: In natural language processing, data acquisition and preprocessing techniques are significant for experiments involving training models on cleaned data. This paper describes the formation of a dataset of ugly and derogatory words in the Serbian language and the development of a web extension to analyze texts in which such words appear and then their censoring. Developing such an add-on is essential in creating a safer and healthier digital environment for young users who are just developing their Internet habits and adults who want to avoid unwanted content. It is crucial to point out that there are few software tools for natural languages with limited resources, such as the Serbian language. This software could analyze the frequency of certain foul words on different sites, which would contribute to a better understanding of the impact of such language on users. -
D.Drašković et al., "Practical teaching in the field of software engineering"
D.Drašković, T.Šekularac-Obradović, M.Ogrizović, L.Hrvačević, T.Radaljac, D.Bojić, "Practical teaching in the field of software engineering", 20th China - Europe International Symposium on Software Engineering Education (CEISEE 2024), Belgrade, Serbia, 2024. (organised by Harbin Institute of Technology and University of Belgrade) [ISBN: 978-86-85525-34-6]
Link: Pogledaj rad u Programu |
Apstrakt: Considering the estimates of the growing demand for software engineers in Serbia and the world, the University of Belgrade - School of Electrical Engineering founded a modern study program in Software Engineering in 2004. In this study program, the segment of the program related to classical electrical engineering has been significantly reduced, but specialized courses are taken from the second semester. A perfect side of this study program is the large number of optional subjects, as well as the great attention focused on practical teaching. Students in this study program are expected to complete homeworks starting from the first year, and in the later years of study, they are working on are larger independent or team projects. This paper describes practical teaching in the subjects of the basics of software engineering, such as principles of software engineering, software design, software testing, and software project management. Ways of working with students through homework and project assignments, laboratory exercises, methods of knowledge transfer, scoring systems, and software tools included in the teaching process are highlighted. -
D.Drašković et al., "Visual simulators in the teaching of artificial intelligence"
D.Drašković, A.Milaković, V.Jocović, B.Nikolić, "Visual simulators in the teaching of artificial intelligence", 20th China - Europe International Symposium on Software Engineering Education (CEISEE 2024), Belgrade, Serbia, 2024. (organised by Harbin Institute of Technology and University of Belgrade) [ISBN: 978-86-85525-34-6]
Link: Pogledaj rad u Programu |
Apstrakt: Teaching machine learning (ML) concepts to students who have no programming experience can be very challenging. In 2021, a visual simulator was introduced in the course Intelligent Systems at the Faculty of Electrical Engineering of the University of Belgrade. This simulator allows students to learn key machine learning concepts without programming, from data selection and preprocessing, hyperparameter selection, and model training. This paper describes the importance of using such simulators in teaching. The paper provides an insight into the results of student success from the previous 6 academic years, which show an increase in student performance through higher passing rates, better grades and a greater number of students achieving the highest grades. This analysis suggests that simulators have an important role in the learning process of complex subjects. -
D.Drašković et al., "Prikupljanje podataka i označavanje u procesu formiranja skupova podataka govora mržnje na srpskom jeziku"
D.Drašković, U.Radenković, M.Mićović, J.Cincović, A.Milaković, V.Jocović, "Prikupljanje podataka i označavanje u procesu formiranja skupova podataka govora mržnje na srpskom jeziku", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 93-98, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: Pogledaj rad u Zborniku |
Apstrakt: Govor mržnje predstavlja jedan od najozbiljnijih izazova savremenog digitalnog društva, naročito usled masovne upotrebe društvenih mreža i onlajn medija. Razvoj pouzdanih automatizovanih sistema za njegovu detekciju zahteva postojanje kvalitetnih, pažljivo prikupljenih i anotiranih skupova podataka, što je posebno izazovno za jezike sa ograničenim digitalnim resursima, kao što je srpski jezik. U ovom radu opisan je proces prikupljanja, obrade i označavanja tekstualnih podataka sa ciljem formiranja skupa podataka za detekciju govora mržnje na srpskom jeziku. Podaci su prikupljani sa različitih izvora, uključujući društvene mreže i onlajn medijske platforme, korišćenjem automatizovanih i ručnih tehnika, kao i veb indeksiranja i prikupljanja. Formirani skup sadrži 4300 kratkih tekstova koji su anotirani u tri klase: tekst bez govora mržnje, uvredljiv govor i govor mržnje, pri čemu je govor mržnje dodatno kategorisan prema relevantnim tipovima diskriminacije u skladu sa aktima Evropske unije. Pored opisa procesa anotacije, u radu je data i detaljna analiza skupa podataka, uključujući distribuciju klasa, dužinu tekstova i najčešće specifične reči. Predstavljeni rezultati ukazuju na složenost i raznolikost govora mržnje u onlajn komunikaciji na srpskom jeziku i predstavljaju značajnu osnovu za dalji razvoj i evaluaciju sistema zasnovanih na veštačkoj inteligenciji. -
A. Mandić et al., "Primena veštačke inteligencije u analizi i obradi govora kroz transkripciju,verifikaciju i evaluaciju izjava"
Ana Mandić, Marko Jelović, Ana Bulatović, Filip Nikolić, Hana Mijatović, Nikola Vučićević, Ana Stanić, Natalija Bogdanović, Luka Lazović, Anja Mihajlov, Lana Popović, Adrian Milaković, Vladimir Jocović, Dražen Drašković, "Primena veštačke inteligencije u analizi i obradi govora kroz transkripciju,verifikaciju i evaluaciju izjava", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 99-103, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: Pogledaj rad u Zborniku |
Apstrakt: U svetu gde se informacije šire izuzetnom brzinom, često je izazovno razlikovati tačne od netačnih podataka koje dobijamo iz medija. Ručna analiza javnih govora zahteva mnogo vremena i resursa, što je čini nepraktičnom za obradu velikog broja informacija. Kako bi se odgovorilo na ovaj izazov, razvijen je sistem koji kombinuje moć velikih jezičkih modela i pretragu na internetu, omogućavajući automatsku proveru činjenica i pružanje pouzdanih rezultata. Ovakva tehnologija ima široku primenu – od medijskih kuća i istraživačkih timova, do svih onih koji žele da dobiju pouzdane informacije i bolje razumeju sadržaj koji im se plasira. -
V.Matvejev, D.Drašković, "Predviđanje uspešnosti memorizacije slike pomoću modela mašinskog učenja"
V.Matvejev, D.Drašković, "Predviđanje uspešnosti memorizacije slike pomoću modela mašinskog učenja", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 62-65, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: Pogledaj rad u Zborniku |
Apstrakt: Vizuelna pažnja, odnosno automatska selekcija najvažnijih informacija unutar vizuelnog stimulusa, tema je unutar računarske vizije koja zahvata veliko interesovanje naučnika. U ovom istraživanju, fokus je na proučavanju komplikovanog odnosa između implicitne, skrivene (engl. Covert) i eksplicitne, otvorene (engl. Overt) pažnje i ljudske memorije pomoću eksperimenta memorabilnosti na statičnim slikama. 30 slika za eksperiment je odabrano iz FIGRIM [1] skupa slika. Sakupljeni podaci gledanja slika (engl. Eye Tracking Data) korišćeni su najpre za izračunavanje fiksacionih i vizuelnih mapa upečatljivosti, a potom i IOVC metrike (engl. Inter Observer Visual Congruency), koje su zajedno sa procentom uspešne memorizacije slike (memorabilnog skora) bili ključni parametri istraživanja. Značajna korelacija između IOVC skora i skora memorabilnosti ukazala je na mogućnost automatizacije predikcije uspešnosti gledanja slike samo na osnovu njene fiksacione mape. Inspirisano ovim uvidom, najpre je treniran model mašinskog učenja na sakupljenom skupu podataka gledanja, koji je na osnovu fiksacionemape trebalo da zaključi o kojoj od 30 datih slika je reč. Cilj je bio da se istrenira klasifikator koji uspešnomože da razlikuje slike samo na osnovu podataka o njihovom gledanju. MLP arhitektura se pokazala najpreciznijom za ovaj problem višestruke klasifikacije, i taj model je dalje korišćen za nalaženje praga zaključivanja (engl. Inference Thresholding) uspešnosti memorizacije za svaku od 30 slika. Istrenirani model je imao tačnost blizu 90%u određivanju da li proizvoljna fiksaciona mapa vodi uspešnoj memorizaciji date slike. -
M.Dodović et al., "From Documents to Answers: A University-Focused DBQA System with LLMs"
M.Dodović, J.Tufegdžić, L.Hrvačević, D.Drašković, "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 333-343, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_25]
Link: Pogledaj rad u Zborniku |
Apstrakt: This paper presents a document-based question-answering (DBQA) system utilizing a large language model (LLM) to assist students in retrieving relevant information from official university documents. The system effectively processes machine-readable documents by leveraging pre-trained multilingual embeddings and a transformer-based QA model while supporting both Serbian and English queries. The experimental setup focused on extracting relevant context using cosine similarity and answering queries using a fine-tuned QA pipeline, achieving an average accuracy of 84.16%. Evaluation results highlight the system’s strengths in retrieving factual answers while identifying challenges related to answer format variations and partial extractions. This research demonstrates the potential of LLM-based DBQA systems in academic and institutional environments, improving information accessibility for students. -
L.Hrvačević et al., "A Comprehensive Review of Large Language Models for Document-Based Question Answering"
L.Hrvačević, M.Dodović, J.Tufegdžić, D.Drašković, "A Comprehensive Review of Large Language Models for Document-Based Question Answering", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 289-301, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_22]
Link: Pogledaj rad u Zborniku |
Apstrakt: This review paper provides a comprehensive survey of Large Language Models (LLMs) applied to Document-Based Question Answering (DBQA). The rapid advancements in LLMs have transformed DBQA systems by enhancing their capabilities in complex reasoning, multi-hop question answering, and contextual understanding. We explore the historical evolution of QA systems before the introduction of LLMs, followed by an in-depth analysis of datasets, benchmarks, and evaluation metrics that underpin DBQA performance. A key contribution of this work is the categorization of LLMs that can perform DBQA based on linguistic focus, distinguishing between monolingual models tailored for specific languages and multilingual models designed to operate across diverse linguistic contexts. Furthermore, we examine notable LLM architectures, their domain-specific adaptations in areas like healthcare and law, and their performance in handling both structured and unstructured data. -
M.Vučinić et al., "Expense tracker using LLM: Mobile application with scanning receipts issued in Serbia"
M.Vučinić, U.Radenković, M.Mićović, V.Jocović, "Expense tracker using LLM: Mobile application with scanning receipts issued in Serbia", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 517-532, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_38]
Link: Pogledaj rad u Zborniku |
Apstrakt: With the increase in available products and services, unplanned spending has become an indispensable part of everyday life. Planning finances and savings for the future has become a struggle for many. Numerous methods that can be used to track expenses, both modern and traditional, are available. Mobile applications are becoming increasingly popular for tracking and planning personal finances, over traditional approaches like paper and spreadsheets, especially among the younger generation. This paper proposes the implementation of the expense tracking application, providing functionalities that will accelerate input of expenses, such as adding transactions with receipt scanning and automatic categorization. Users can easily add transactions, through an intuitive user interface, by scanning the QR code on the receipt (issued in the Republic of Serbia) or manually. The bill data and items are fetched from the Tax Administration office website. Expenses are automatically categorized and summarized based on bill items using the Large Language Models (LLMs) with minimal user engagement. Classifying costs based on bill items leads to greater precision compared to classifying based on location which is used by most other applications. The charts show the amount of money spent across categories on a monthly and annual level. It is possible to set a limit for each month and observe whether the limit is exceeded over time to achieve more sustainable spending. -
D.Drašković, "Integration of AI tools into an AI-driven software system to make learning programming easier"
D.Drašković, "Integration of AI tools into an AI-driven software system to make learning programming easier", 2025 IEEE Global Engineering Education Conference (EDUCON), London, United Kingdom, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/EDUCON62633.2025.11016313]
Link: Pogledaj rad na konferenciji |
Apstrakt: Today, a person can be considered fully digitally literate if they know how to use and integrate ready-made artificial intelligence (AI) tools. The use of AI tools is becoming increasingly common in students' learning processes. However, learning programming can be challenging and exhausting, especially for younger learners. In this research, a software system was developed to integrate multiple AI tools to facilitate the learning process. The system includes tools for speech and text processing, program code generation, code testing, and result verification. Through a user-friendly software interface, users can define a problem or programming task using speech. The software then converts the speech into text using the Whisper AI API, which is subsequently processed by the GPT-3.5 Turbo and Claude AI APIs to generate program code. Once the program code is generated, it undergoes a series of tests, including parallel testing on the LeetCode platform. Users then compare the obtained results and manually complete a survey evaluating both external tools. One key research requirement was for the software system to accept input data in Serbian, a language with limited resources and complex grammatical rules. This made it difficult to find a suitable AI tool for accurate speech-to-text transformation. The system was tested with speech in both English and Serbian but supports many additional languages thanks to the powerful Whisper AI API. The implemented system is modular and easily extensible with new APIs, making it applicable to other areas of education beyond programming. -
V.Milutinović et al., "Applied AI, Teamwork, and Learning in Student Hackathons: Case Study from Serbia"
V.Milutinović, J.Cincović, V.Jocović, D.Drašković, "Applied AI, Teamwork, and Learning in Student Hackathons: Case Study from Serbia", 2025 12th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Cacak, Serbia, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/IcETRAN66854.2025.11114198]
Link: Pogledaj Zbornik radova |
Apstrakt: Student hackathons have emerged as a dynamic educational mechanism for fostering creativity and accelerating the adoption of new technologies among Computer Science and Software Engineering students. First introduced in university settings in the early 2000s, hackathons have evolved into highly engaging events where students compete to develop innovative software or hardware solutions within a limited time frame. The competitive spirit inherent to hackathons resonates strongly with today's engineering students, motivating them to push boundaries, solve real-world problems, and collaborate effectively under pressure. Participation in hackathons enhances students' technical skills, promotes teamwork, and deepens their understanding of modern tools, frameworks, and platforms not always covered in formal curricula. Over the past five years, hackathons have gained remarkable popularity in Serbia, especially at state faculties and through active student organizations. Many of these events are organized in partnership with globally recognized ICT companies, providing students with valuable exposure to industry standards and expectations. At the University of Belgrade, the students' programmers' club, within the Google Developer Group on Campus program, has successfully hosted numerous hackathons that have become key platforms for skill development and innovation. These events not only contribute to academic growth but also significantly enhance students' employability and entrepreneurial thinking. Through hands-on experience and interaction with industry mentors, participants often gain clarity about their professional interests and career paths. Hackathons thus serve as bridges between university education and real-world software engineering practice, preparing students for both modern studies and the tech industry. -
S.Stanković et al., "Comparative Analysis of Machine Learning and Federated Learning in Healthcare"
S.Stanković, P.Vuletić, D.Drašković, "Comparative Analysis of Machine Learning and Federated Learning in Healthcare", 2025 12th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Cacak, Serbia, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/IcETRAN66854.2025.11114237]
Link: Pogledaj Zbornik radova |
Apstrakt: With a rapid development of artificial intelligence in healthcare, machine learning and federated learning has emerged as critical technologies for improving decision-making, diagnostics and personalized treatments. This paper presents a comprehensive comparison between traditional machine learning and newer federated approach, focusing on their applications in healthcare. Even though machine learning provides great efficiency in resolving complex tasks in healthcare, it faces great challenges such as data privacy, security and communication cost. In contrast, federated learning offers a decentralized approach which resolves these limitations and allows healthcare institutions to collaboratively train models across multiple devices and locations without sharing sensitive patient data. The experiment conducted in this study utilized a medical dataset to predict whether an individual is an alcohol consumer or not. A range of metrics, including loss, accuracy, precision, recall, AUC, and F1 score, were employed to evaluate and compare the performances of both approaches. By leveraging this technique, federated learning addresses privacy concerns, while maintaining high model performances across distributed dataset. Experiments conducted on healthcare datasets highlight the strengths, challenges and limitations of both machine and federated learning in practical, real-world scenarios. -
D.Bojić, D.Drašković, "Modernizing 90s Era Software to a New Language and Environment Using LLMs - An Empirical Investigation"
D.Bojić, D.Drašković, "Modernizing 90s Era Software to a New Language and Environment Using LLMs - An Empirical Investigation", INTERNATIONAL JOURNAL OF SOFTWARE ENGINEERING AND KNOWLEDGE ENGINEERING, Vol. 35, No. 8, pp. 1099 - 1119, May, 2025 [DOI: https://doi.org/10.1142/S021819402550024X]
Link: Rad u žurnalu |
Apstrakt Legacy software, particularly from the 1990s, often becomes obsolete due to aging hardware and outdated software environments. Traditionally, software modernization required extensive manual effort, involving reverse engineering, code rewriting, and re-architecting. However, advancements in large language models (LLMs) have introduced new possibilities for automating software translation and modernization. This paper explores the feasibility of using LLMs for modernizing 90s-era Windows applications, specifically migrating legacy C and C++ code to Python. Our methodology includes decompilation, source code analysis, automated translation using ChatGPT, and user interface reconstruction. We empirically evaluate three software projects by analyzing LLM-based translation accuracy across different code structures, including algorithmic logic, file handling, and graphical interfaces. Results indicate that while LLMs achieve high translation accuracy (~88%) for structured code, challenges persist in handling decompiled code and user interface generation. The study provides insights into the effectiveness and limitations of LLMs in real-world software renovation, offering guidelines for leveraging machine learning in legacy system modernization. These findings contribute to both academic research and practical applications, suggesting a pathway for cost-effective and scalable legacy software migration. -
D.Drašković, S.Milanović, "Aspect-based sentiment analysis of user-generated content from a microblogging platform"
Drašković, D., Milanović, S., "Aspect-based sentiment analysis of user-generated content from a microblogging platform," Journal of Big Data 12, 186 (2025) [DOI: https://doi.org/10.1186/s40537-025-01244-0]
Link: Pogledaj rad u žurnalu |
Apstrakt: This research presents a practical application of advanced natural language processing techniques to understand people’s feelings during the global Covid-19 pandemic, using a set of big data of over 547 thousand tweets. Companies often use sentiment analysis to process comments, product usage, social media posts, and more, in order to better understand user needs and preferences. In this research paper, aspect-based sentiment analysis is applied as one of the most recent and advanced subtypes of sentiment analysis. Aspect-based sentiment analysis is a modern natural language processing technique that does not perform sentiment detection at the level of the entire input text but individually over all the aspects detected in it. Therefore, this technique enables the precision of analyzing the user data set and making concrete conclusions about people’s feelings. This research aims to develop a software infrastructure for further work in natural language processing using the aspect-based sentiment analysis technique. The proposed process flow and data handling methods, as defined in this research, are designed to be easily adaptable to other data sets with minimal modifications. -
U.Radenković et al., "Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian"
U. Radenković, J. Cincović, A. Milaković, M. Mićović, M. Dodović, V. Jocović, D. Drašković, "Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 409 - 414, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
Apstrakt: This study focuses on the comparison between human annotation and large language model (LLM)-based annotation of hate speech in Serbian. The dataset consists of short user-generated texts collected from online media portals and social networks. Manual annotation was performed by an expert annotator following detailed labeling guidelines, serving as the reference standard. Automated annotation was conducted using several state-of-the-art LLMs, including GPT-5, Gemini 2.5 Pro, Claude 4, and DeepSeek-R1. The results highlight a strong alignment between human annotation and LLM-based annotation, with GPT-5 achieving the closest agreement with the human annotator. Furthermore, comparative analysis among the top-performing LLMs reveals that, with appropriate fine-tuning, automated annotation can be considered a reliable complement, or in certain contexts, an alternative to manual labeling. -
J.Tufegdžić et al., "LLM-Driven Hate Speech Detection in News Content Extracted from URLs"
J. Tufegdžić, L. Hrvačević, M. Dodović, N. Stanković, D. Drašković, "LLM-Driven Hate Speech Detection in News Content Extracted from URLs," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 415 - 420, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
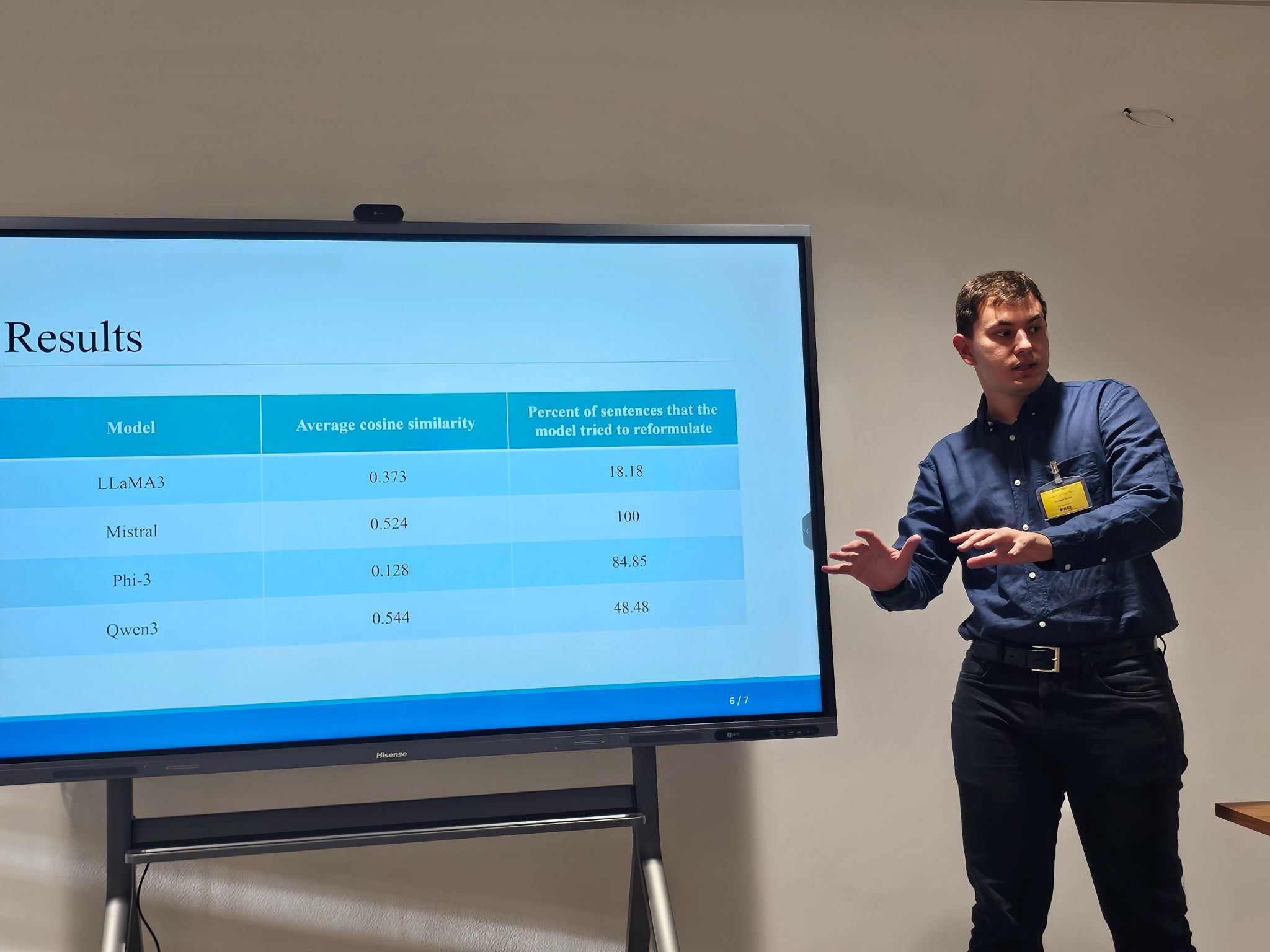
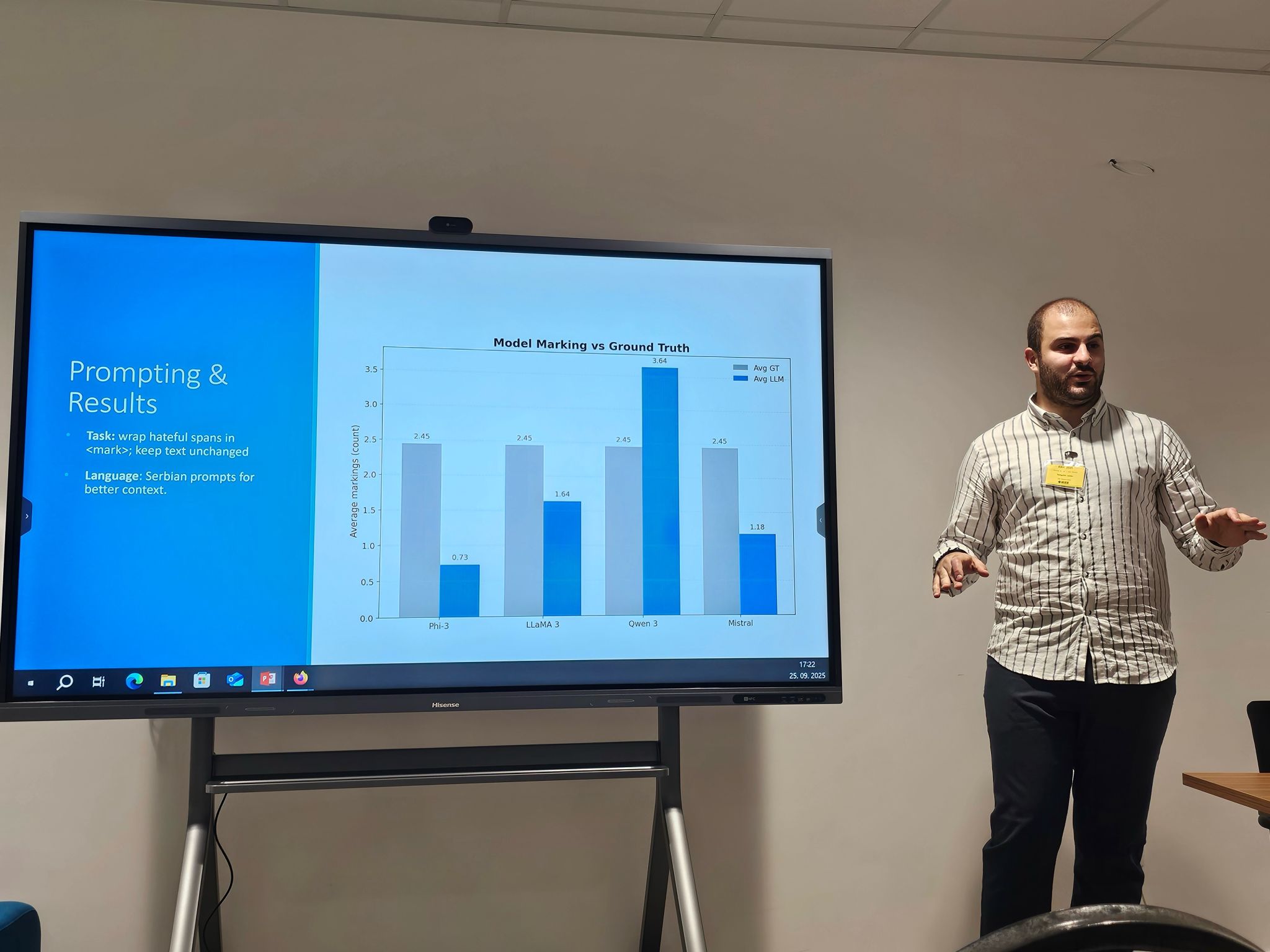
Apstrakt: This paper presents a system for detecting hate speech in Serbian language in online news articles using large language models (LLMs). While most prior work focuses on social media platforms, news content poses unique challenges due to more subtle, implicit, and editorially framed expressions of hate speech. Our approach integrates a web scraper that extracts clean text from article URLs and a prompt-based LLM classifier that highlights hateful segments without altering the original structure. The research analyzes content in the Serbian language, which is one of the languages with limited resources, but the methodology can be adapted and applied to other languages. To evaluate the system, we tested it on live articles from online Serbian media known for publishing content with hate speech, based on previously annotated datasets from related 2023 studies. We evaluate four state-of-the-art LLMs: LLaMA 3, Mistral, Phi-3, and Qwen3, on a curated dataset of Serbian news articles with human-labeled annotations. Results show that LLaMA 3 most closely aligns with human judgments, while Qwen3 tends to over-tag, and Mistral and Phi-3 often under-tag hate speech. The entire system, including the web interface, is available as open source. Our findings highlight the potential of LLMs for reliable hate speech detection in formal, long-form content and demonstrate the importance of model choice and prompt design for balanced moderation. -
M.Dodović et al., "From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs"
M. Dodović, N. Stanković, J. Tufegdžić, L. Hrvačević, D. Drašković, "From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 421 - 426, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
Apstrakt: This paper presents a system for rewriting hate speech in the Serbian language using large language models (LLMs) to produce culturally appropriate and neutral reformulations. Our approach centers around content purification, which includes removal of hateful, offensive, or discriminatory elements from a sentence while preserving its original intent when possible. The research analyzes content in the Serbian language, which is one of the languages with limited resources, but the methodology can be adapted and applied to other languages as well. The core of the system is a carefully designed prompt, instructing the model to either rewrite the sentence with improved tone or replace it entirely with a neutral message if there is no valuable content. We evaluate four state-of-the-art LLMs: LLaMA 3, Mistral, Phi-3, and Qwen3, using a curated dataset of hate speech examples in Serbian, extracted from comments left on Serbian news articles. The models are run locally using the Ollama framework, ensuring full data privacy and control. Results indicate that Mistral and Qwen3 offer the most consistent and context-aware rewrites, while other models show varying sensitivity to different types of hate speech. Our findings emphasize the effectiveness of prompt-based LLM interaction for hate speech moderation and highlight the importance of prompt design, and model selection in sensitive language-processing tasks. -
V.Matvejev et al., "Web Application for Predicting Image Memorability Using a Machine Learning Model"
V.Matvejev, D.Drašković, B.Nikolić, D.Bojić, "Web Application for Predicting Image Memorability Using a Machine Learning Model", 2025 33rd Telecommunications Forum (TELFOR), Belgrade, Serbia, 2025, pp. 1-4 [DOI: https://doi.org/10.1109/TELFOR67910.2025.11314318]
Link: Pogledaj rad |
Apstrakt: Visual attention i.e. the automatic selection of the most important information within a visual stimulus - is a topic within computer vision that attracts considerable scholarly interest. In this study, the focus was on examining the complex relationship between covert (implicit, hidden) and overt (explicit, observable) attention and human memory through a memorability experiment on static images. Thirty images for the experiment were selected from the FIGRIM dataset. The collected eye-tracking data were first used to compute fixation maps and visual saliency maps, and then the IOVC (Inter-Observer Visual Congruency) metric; together with the percentage of successful image memorization (the memorability score), these served as the key parameters of the study. A significant correlation between the IOVC score and the memorability score indicated the possibility of automating the prediction of whether viewing an image would lead to successful memorization based solely on its fixation map. Inspired by this insight, we first trained a machine learning model on the collected viewing data to infer, from a fixation map, which of the 30 images had been viewed. The goal was to train a classifier capable of distinguishing images using only their viewing (eye-tracking) data. The trained model achieved close to 90% accuracy in determining whether an arbitrary fixation map would lead to successful memorization of the given image. A web application that could be used for commercial use for memorability prediction was developed. -
D.Drašković et al., "Using generative AI in hate speech detection for primary and secondary school students"
D.Drašković, J.Cincović, U.Radenković, V.Jocović, M.Mićović, A.Milaković, "Using generative AI in hate speech detection for primary and secondary school students", 2025 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), pp. 1 - 7, IEEE, Macao, Dec, 2025 [DOI: https://ieeexplore.ieee.org/document/11346657]
Link: Pogledaj rad na konferenciji |
Apstrakt: Hate speech among children in primary and secondary schools represents a widespread and concerning phenomenon. It is unrealistic to expect young individuals to refrain from discriminatory behavior if they are regularly exposed to hateful rhetoric in their environment. This research focuses on the design and development of a web-based application for the detection and classification of hate speech in the Serbian language, with the broader goal of supporting efforts to reduce hate speech among school-aged children. Serbian, as a South Slavic language with limited natural language processing resources, poses additional challenges for computational analysis compared to globally dominant languages due to the scarcity of publicly available datasets. The implemented software tool leverages generative artificial intelligence, specifically state-of-the-art large language models including GPT-4o, Claude 4, Gemini 2.5-Pro, Llama 3, and DeepSeek-R1. The tool is intended for use in educational contexts in Serbia, providing functionality for the analysis of textual content prior to its publication on internet portals and social media platforms. Key features include the automatic detection of hate speech and the generation of revised, nonhateful versions of the text while preserving its original intent. -
M.Stanojević, D.Drašković, "Razvoj infrastrukture za upravljanje Docker kontejnerima i velikim jezičkim modelima"
M.Stanojević, D.Drašković, "Razvoj infrastrukture za upravljanje Docker kontejnerima i velikim jezičkim modelima", Zbornik radova 32. IKT konferencije "YU INFO 2026", Informaciono društvo Srbije, pp. 1-6, Kopaonik, Serbia, March 2026 []
Link: Vidi rad u Zborniku (in publishing!) |
Apstrakt: Sa sve većom primenom velikih jezičkih modela u različitim oblastima, od obrade prirodnog jezika, preko inteligentnih asistenata, do automatizacije složenih poslovnih procesa, javlja se potreba za efikasnim, pouzdanim i standardizovanim sistemima koji omogućavaju njihovo jednostavno pokretanje, održavanje i skalabilno upravljanje. Veliki jezički modeli zahtevaju hardverske resurse, specifična okruženja za izvršavanje i pažljivo planirane mehanizme za raspoređivanje i potpuno upravljanje verzijama izvornog koda, što dodatno naglašava važnost dobro osmišljene infrastrukture. Istovremeno, Docker kontejneri su postali jedan od ključnih elemenata savremenih softverskih arhitektura. U ovom radu posebna pažnja biće posvećena arhitekturi sistema, organizaciji i automatizaciji procesa, kao i integraciji modela u složena, industrijska okruženja.
Kontaktirajte nas
Adresa:
Beograd 11000, Bulevar kralja Aleksandra 73
E-pošta:
stop@lists.etf.rs