


News
The latest news from our project team will be published in this section.

Interview for Radio Beograd 202
14.5.2026.
Our PI, Dr. Dražen Drašković, participated in the radio show "Pravac 202" on May 12, 2026. The episode, titled "Arguing with Inanimate Objects" and hosted by Jelena Knežević and Kruna Pintarić, featured a discussion with Dražen on how to better utilize artificial intelligence models instead of getting frustrated with them, and how AI helps ensure the digital environment does not become a threatening and unsafe space. The show also highlighted the STOP software, designed to prevent cyberbullying among youth in Serbia. You can listen to the full episode HERE.


Build with AI 2026 Conference & Hackathon
31.3.2026.
At the Build with AI 2026 Hackathon, held last weekend (March 27-29, 2026) at the Palace of Science, organized by Google Developer Group Belgrade & ETF Belgrade, developers, innovators, and tech enthusiasts gathered to collaborate and build cutting-edge AI solutions. Three lectures were delivered at the conference, covering the topics of:
- AI Agents Face-Off: Same App, Multiple frameworks (lecturer: Elaine Dias Batista)
- Way Back Home Series - Mission I: Identify Yourself (lecturer: Konstantinos Kechagias)
- VLM System Design for an AI Assistant (lecturer: Darya Vinogradova)


Following the conference, a 36-hour hackathon was organized, featuring 10 teams of 3 to 4 students. Our team members also participated in this event as mentors and judges, contributing their expertise and supporting the participants.




Interview for RTS 1
20.3.2026.
A member of our team, dr Jelica Cincović, appeared as a guest on the show „Naučni portal“ (RTS - Serbian Broadcasting Corporation) to present our project. During the interview, she explained how the software for detecting hate speech in the Serbian language works, why this tool is important, and where it can be applied in practice. The full episode can be watched HERE.

DEV FEST 2025
1.12.2025.
DevFest 2025, a hackathon and conference, was a three-day innovative tech event held from November 28th to 30th, 2025, at the Palace of Science – Miodrag Kostić Endowment. The event was organized by the Google Developer Group on Campus - University of Belgrade, and the Data Analysis and Applied Artificial Intelligence Laboratory at the University of Belgrade, School of Electrical Engineering.


The event brought together 10 teams and 39 competitors who worked intensively to develop creative and technically demanding solutions focused on applying artificial intelligence to mobile applications. Following the final presentations, the jury announced the winner: team Tech Turtles with their project "Tempi".
This competition was supported by the project team of the national research project STOP (#11113), funded by the Science Fund of the Republic of Serbia, with the aim of promoting a wider application of artificial intelligence and large language models in software development.



Participation at the IEEE ERK Conference 2025 in Portorož
1.10.2025.
Our researchers from the University of Belgrade, School of Electrical Engineering presented our project's scientific results in the fields of natural language processing and automatic hate speech detection in the Serbian language at the 34th International Electrotechnical and Computer Science Conference (ERK) in Portorož, Slovenia.


The STOP project was presented through 3 scientific papers:
- Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian
- LLM-Driven Hate Speech Detection in News Content Extracted from URLs
- From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs

A Weekend Full of Innovation: The “Build with AI” Hackathon Successfully Held!
05.05.2025.
📢 "Build with AI", an innovative student hackathon, was held on May 3–4, 2025,
at the Palace of Science, organized by the Google Developer Group on Campus, University of Belgrade,
and the Laboratory for Data Analysis and Applied AI at the School of Electrical Engineering.
Ten teams participated, and after 36 hours of intense work, nine presented their projects.
The winners were:
🥇 Vibe Coders – Safe Space
🥈 Charmander – Better Search
🥉 Debug Divas – Lumi & VTŠ AppsTeam – Hate Guard
Congrats to all the teams for their creativity and effort!
Special thanks to Gerard Sans, Dr Dražen Drašković, Vanja Milutinović, and our STOP team: Dr Vladimir Jocović and Jelica Cincović.

Visit to the center for the application of artificial intelligence within the Palace of Science
17.01.2025.
📢 Today, we held our regular monthly meeting in our new research laboratory for applied artificial intelligence in the beautiful Palace of Science - Miodrag Kostić Foundation in Belgrade.
We preprocessed the inconsistent labelled data at our meeting and prepared them for new project activities and the next phase of developing the first models. We also agreed to write new scientific publications in this project quarter. At the end of the day, we toured the permanent exhibition at the Palace of Science and socialized with preschool students to open the magical doors of science to them.
We look forward to the year ahead in the new premises, with new challenges in the project, and we wish all the followers a lot of happiness and success.

Interview for TV show - Knowledge Studio
07.12.2024.
📢 A member of our team, Jelica Cincović, recently presented the STOP project on the TV show "Knowledge studio". The topic of the show was: Artificial intelligence in education. You can watch the video HERE.

Participation in the CEISEE 2024
03.10.2024.
The 20-th China-Europe International Symposium on Software Engineering Education (CEISEE 2024) has taken place on 2-3 October in Belgrade. The first day of the conference was held at the School of Electrical Engineering, University of Belgrade, and the second day at the Palace of Serbia. Our team members presented their papers and throughout the rich exchange of knowledge with collegues from China, we are poised to embark on exciting new innovative ventures. This collaboration fosters creativity and paves the way for groundbreaking projects.




Interview for NOVA TV
15.7.2024.
📢 The principal investigator of our project, Dr. Dražen Drašković was a guest on Nova TV television's morning program, where he spoke about this year's enrollment of high school students at the University of Belgrade, School of Electrical Engineering, the impact of artificial intelligence on information technology, as well as the STOP project, financed by the Science Fund of the Republic of Serbia in which we develop a software system for detecting hate speech in Serbian. He pointed out that the decrease in the number of applicants for IT departments at universities was mostly influenced by depopulation and more than 4 thousand graduates of four-year secondary schools You can watch the video HERE.
Regular monthly project team meeting
2.7.2024.
📢 The STOP project team held a regular monthly meeting at the School of Electrical Engineering 🏫 At the meeting, an analysis of the previous work was done and a semi-annual report was written, which was submitted to the Science Fund. The team concluded that all planned activities were successfully carried out and that all required deliverables were achieved. During the summer, we expect to arrange the database of short texts in the Serbian language and label the data, as well as the completion of the survey scientific paper, which we are preparing for publication in an international journal. Continue to follow our activities!


Participation in the round table of the XIX International Symposium - "SymOrg 2024"
15.6.2024.
On Saturday, June 15, 2024, as part of the XIX international symposium SymOrg 2024, the Faculty of Organizational Sciences organized a panel (round table). The panel's topic was "Synergy of Humans and Technology in Higher Education," and Dr. Dražen Drašković, head of our STOP project, participated in the panel among deans and faculty representatives from the entire region. Dr. Drašković spoke about the extraordinary cooperation between the School of Electrical Engineering (ETF) and the Faculty of Organizational Sciences (FON) in Belgrade on joint master's studies in digital transformation, the challenges that arose in teaching with the introduction of artificial intelligence tools and during the coronavirus pandemic, and he also highlighted the new software systems that we are developing within Laboratories for data analysis and application of artificial intelligence, including a tool from the STOP project.


Participation in an international conference IcETRAN 2024
7.6.2024.
The STOP team participated in the International Conference IcETRAN, held in Niš, from June 3 to 6, organized by the Society for ETRAN and the Faculty of Electronics in Niš. Members of our team presented work on the application of large language models and participated in the work of this traditional conference.

Interview for K1 television
28.5.2024.
Our project investigator, Dr. Dražen Drašković, spoke in the morning program "Uranak" on television station K1 about the STOP project, which is being developed in the Laboratory for data analysis and application of artificial intelligence at the School of Electrical Engineering in Belgrade. You can watch the video HERE.

Participation in The Third Serbian International Conference on Applied Artificial Intelligence
25.5.2024.
The STOP team participated in The Third Serbian International Conference on Applied Artificial Intelligence (SICAAI) held in Kragujevac on May 23th and 24th. Our team members Drazen Draskovic and Jelica Cincovic held presentations on the topics of detecting hate speech in the Serbian language, and data analysis techniques and detecting propaganda in the Serbian language. Our paper entitled Applied Artificial Intelligence in detecting Hate Speech received the award for the best student paper in Mini-Symposium VII: Heritage Mining: Theory and Examples.

Congratulations to our team member Uroš Radenković
24.5.2024.
On Wednesday, May 22, 2024, a member of our project STOP team, Uroš Radenković, successfully defended his doctoral dissertation entitled "Speculative execution of instructions with imprecisely predicted operands". We congratulate Uroš on achieving the title of Doctor of Science in Electrical Engineering and Computing, and we wish him much success in his further scientific work!

Congratulations to our team member Dr. Vladimir Jocović on the award for the best PhD
15.5.2024.
On Wednesday, May 15, 2024, a member of our STOP project team, Dr. Vladimir Jocović, was awarded the best doctorate in computer science for the year 2023. Vladimir received an award for his doctoral dissertation defended in December 2023 at the Faculty of Electrical Engineering, University of Belgrade, entitled "Automated evaluation of paper tests using artificial intelligence techniques", under the mentorship of prof. Dr. Boško Nikolić and Assoc. Dr. Saša Stojanović. The prize is awarded by the Mathematical Institute of the Serbian Academy of Sciences and Arts (MI-SASA).
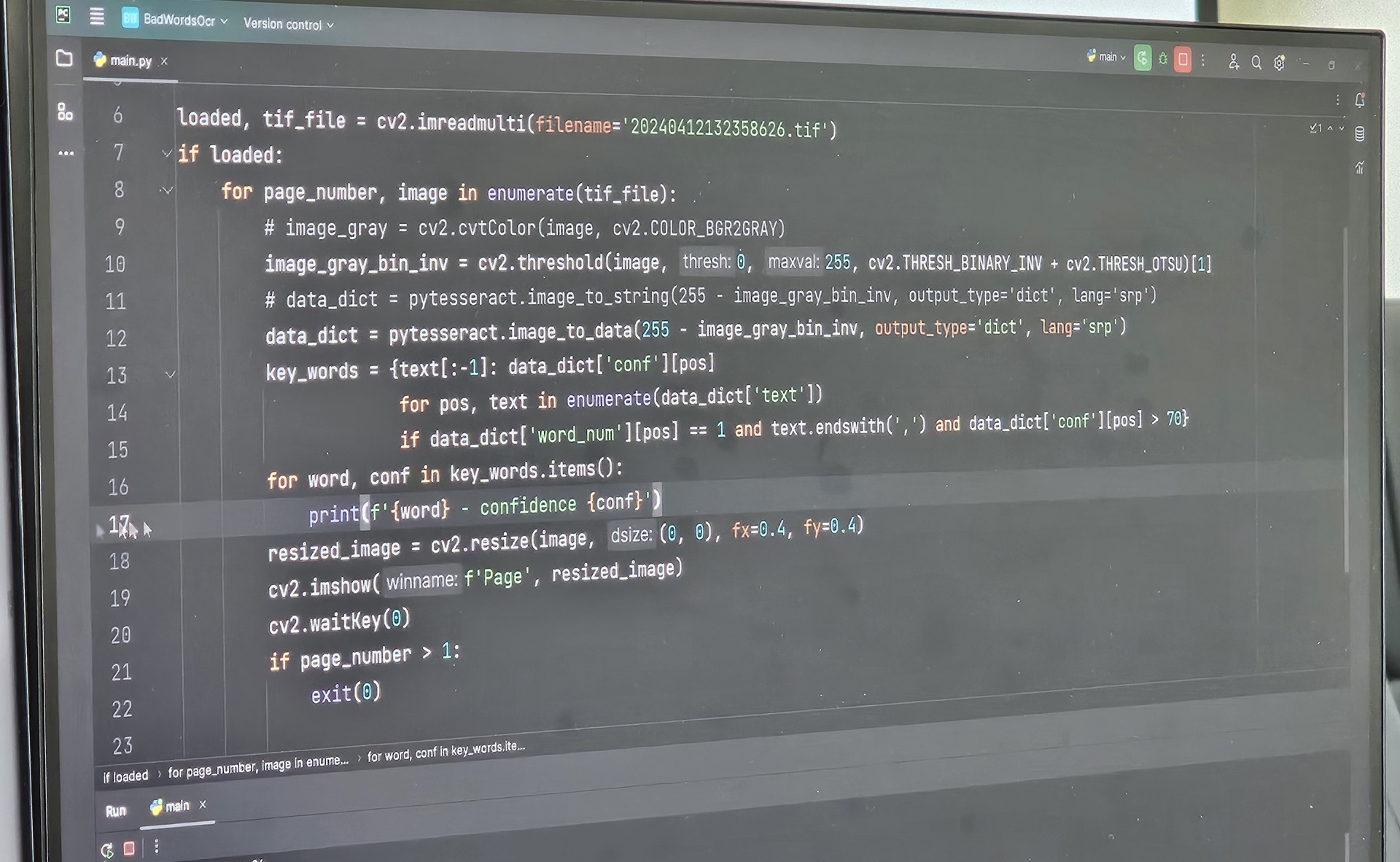
A corpus of ugly and derogatory words in the Serbian language has been created
15.4.2024.
During February and March, our STOP project team worked on collecting and developing a corpus of ugly and derogatory words in the Serbian language (result of D2.1 of the project plan). The words are collected from various sources, from websites and portals, from digital and printed dictionaries of the Serbian language, which were then scanned and where optical character recognition (OCR) techniques were used, as well as manual data labeling. The results are shown in the section Resources.
Participation in the Serbian-Chinese conference on the development of artificial intelligence
12.4.2024.
Yesterday, our team participated in a conference dedicated to the development of artificial intelligence, organized by the Science Fund of the Republic of Serbia and the National Science Foundation of the Republic of China. The aim of the conference was to introduce researchers from the two countries and to present previous projects in this field. We thank the Science Fund for being part of this interesting scientific event.
The second review meeting
3.4.2024.
📢 The STOP project team met today, in the meeting room of the School of Electrical Engineering 🏫 At the meeting, tasks for the upcoming quarter were divided 📝 We are working diligently on the first hate speech detection software in the Serbian language, and we look forward to the new challenges ahead!


Formal ceremony of promotion of awarded projects from the project cycle "Program of young researchers - PROMIS 2023"
20.3.2024.
On Wednesday, March 20, 2024, a celebration was held on the occasion of five years of existence of the Science Fund of the Republic of Serbia. During the celebration, the attendees were addressed by the acting director of the Fund for Science Ms Milica Đurić-Jovičić, PhD, the Minister of Science, Technological Development, and Innovation, Ms Jelena Begović, PhD, as well as representatives of the European Union and the World Bank. At the celebration, managers of approved projects from the PROMIS 2023 call and projects that were awarded and received two-year funding from the Science Fund of the Republic of Serbia were especially highlighted.

Panel on cyber security trends and challenges
15.3.2024.
As part of the jubilee 30th national scientific and professional conference "YU INFO", our team organized a special event - an expert panel, on the topic "Cyber security trends and challenges in the protection of large systems", on Tuesday, March 12, 2024 in the congress hall "Pancic A" in the hotel "Grand" at the ski resort Kopaonik.
The panel was moderated and designed by the PI of our "STOP" project, Prof. Dr. Dražen Drašković. The following researchers took part in this panel: prof. Dr. Slavko Gajin (Faculty of Mathematics in Belgrade), Ass. professor Dr. Maja Vukasović (School of Electrical Engineering in Belgrade), Master of Legal Sciences Bojana Marinković (University Newcastle, UK) and B.Sc. Eng. Marko Džida (Serbia And Montenegro Air Traffic Services Smatsa Llc).
In the past few years, cyber threats have become increasingly important for organizations and their large systems, and user data is very often under attack by malicious users (hackers). In the last year, many large software systems crashed in Serbia and the region. The panel discussed effective security measures, regulatory requirements (such as GDPR and HIPAA), good practices in organizations in Serbia and the world, the boundaries between the application of robust security measures and system maintenance, which data are dangerous to misuse, and many other questions. The panel attracted interested conference participants with interesting questions, so the discussion was fruitful and useful.


Participation of our researchers at the "YU INFO 2024" and "ICIST 2024" conferences
12.3.2024.
From March 10 to 13, 2024, the jubilee 30th ICT conference, "YU INFO 2024," and the 14th international conference, "ICIST 2024," were held at the ski resort Kopaonik, in which more than 350 participants from Serbia and the world took part. This year's conferences were mostly about artificial intelligence, big data processing, and large language models. At the conferences, 73 papers were presented in seven sessions at the national level and 92 papers at the international level. The conference program is available at the following link.
On Monday, March 10, 2024, in the scientific session "Pre-trained Large Language Models" at the international conference "ICIST 2024", our team presented a paper entitled "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", and on Tuesday, March 11, in the scientific session "Artificial Intelligence and Machine Learning" within the national conference "YU INFO 2024", a paper titled "AI-driven hate speech detection" was presented. Both scientific papers were created as a result of our project in the first two months of our research.

The kick-off meeting
10.1.2024.
In the meeting room of the School of Electrical Engineering, the STOP project team held an initial meeting on Wednesday, January 10, 2024. The Principal Investigator distributed the tasks to the members for the first month of the project and presented an overview of the half-yearly goals.


Project information
Acronym: STOP
The result of the researchers' collaboration will be a new software system that will detect hate speech in the Serbian language and will be of great importance in prevention of digital violence in Serbia.
Period: jan. 2024 - dec. 2025 | Budget: 140,000.00 €
The research problem addressed by this project is detecting hate speech (HS) in texts in Serbian on the Internet. Detecting and reducing HS is crucial for the safety and well-being of individuals, as it can otherwise lead to real-world harm and tragedies. Traditional methods of manually monitoring online content are time-consuming, costly, and ineffective in dealing with the vast amount of user-generated content. Therefore, there is a need for automated tools that can efficiently detect and prevent HS, which compose the primary goals of this project. This project also marks a significant milestone as the first-ever initiative to develop HS detection models designed exclusively for the Serbian language.
The impact of this project is remarkable. The software protects individuals from online abuse and violence by detecting and preventing HS. The project's research findings, including the developed dataset, NLP models, and software system, can advance the field of hate speech detection in the Serbian language and impact various sectors, including healthcare, education, science, and industry.
-
Participating Scientific-research organizations:
- University of Belgrade - School of Electrical Engineering (ETF)




Team members
The team consists of researchers from the School of Electrical Engineering, University of Belgrade

Prof. Dražen Drašković, PhD
Principal Investigator
Ass. Prof. Vladimir Jocović, PhD
Member of the project team
Marko Mićović, PhD candidate
Member of the project team
Ass. Uroš Radenković, PhD
Member of the project team
Jelica Cincović, PhD candidate
Member of the project team
Adrian Milaković, PhD candidate
Member of the project teamResources
This section will show the resources that will be published during the project.
Resource D2.1. - A corpus of ugly and derogatory words in Serbian language
published 4.4.2024.
This result contains:
- Dictionary of derogatory names by category (D2.1a)
- Dictionary of folk derogatory expressions (D2.1b)
Resource D2.a. - Web extension for removing ugly and derogatory words in the Serbian language
published 16.10.2024.
This result contains:
- A web extension for the Google Chrome web browser
Published papers
Papers from conferences and scientific journals will be published in this section. ( Access password: StopETF! )
-
D.Drašković et al., "Otkrivanje govora mržnje vođeno veštačkom inteligencijom" (in Serbian; english "AI-driven hate speech detection")
"Otkrivanje govora mržnje vođeno veštačkom inteligencijom", Zbornik radova 30. IKT konferencije "YU INFO 2024", Informaciono društvo Srbije, pp. 182-186, Kopaonik, Serbia, March 2024 [ISBN: 978-86-85525-31-5]
Link: Read paper |
Link: Proceedings of the conference |
Abstract: Hate speech is anything that offends an individual, population or phenomenon on any basis, which can be sexual orientation, belonging to a religion, nationality, race, belonging to a certain group, expressed views or other. Detecting and reducing hate speech is critical to the safety and well-being of individuals, as such speech can otherwise lead to harm and tragedy in the real world. Traditional methods of manually monitoring content on the Internet are time-consuming, expensive, and inefficient when dealing with huge amounts of user content. Therefore, there is a need for the development of automated tools that can effectively detect or prevent the publication of hate speech, and which constitute the primary objectives of this research. This research represents a significant milestone as the first initiative for the development of a hate speech detection model designed for the Serbian language. In this paper, an analysis of existing techniques that detect and classify hate speech in other languages is given, and a model proposal is also given, which will be developed for the detection and classification of hate speech in the Serbian language. The research is conducted within the national project “Software for Text Offences Prevention in Serbian: Al-driven Hate Speech Detection”, financed by the Science Fund of the Republic of Serbia in the period 2024-2025. -
M.Dodović et al., "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation"
M.Dodović, M.Ogrizović, D.Miladinović, D.Drašković, "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", Springer's Lecture Notes in Networks and Systems, with title Disruptive Information Technologies for a Smart Society, vol 860, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-031-71419-1_30]
Link: View paper in Proceedings |
Abstract: Sentiment analysis, a pivotal aspect of NLP (Natural Language Processing), of-fers profound insights into the public sentiment from vast swathes of unstruc-tured textual data. This paper presents an empirical investigation into the applica-bility and effectiveness of the BERT (Bidirectional Encoder Representations from Transformers) algorithm for sentiment analysis, particularly focused on product reviews. The research delves into the nuances of consumer language expressions and evaluates the capacity of BERT to accurately classify sentiment in a large-scale dataset of food product reviews. The results achieved through this research are significant, with the fine-tuned BERT model demonstrating high accuracies, indicating its robustness and suitability for the sentiment classification task. In addressing the challenges posed by the varying lengths of consumer reviews, this study offers a methodological analysis for selecting the optimal max_seq_length parameter within BERT’s framework. A critical balance is achieved between computational efficiency and the comprehensive inclusion of informative content within the reviews. Furthermore, the paper confronts the prevalent issue of class imbalance in sentiment analysis datasets by employing a weighted loss function during the training of BERT. This technique ensures equi-table representation and consideration of all sentiment classes, enhancing the model's accuracy and fairness. -
J.Cincović et al., "Applied Artificial Intelligence in Detection Hate Speech"
J.Cincović, U.Radenković, M.Mićović, A.Milaković, V.Jocović, D.Drašković, "Applied Artificial Intelligence in Detection Hate Speech", in publication Applied Artificial Intelligence 4: Medicine, Biology, Chemistry, Financial, Games, Engineering AAI 2024 - Lecture Notes in Networks and Systems, vol 1446, Springer, Cham, Kragujevac, May 2024 [DOI: https://doi.org/10.1007/978-3-031-99201-8_11]
Link: View paper in Proceedings |
Abstract: The problem this research addresses is detecting hate speech (HS) in texts in Serbian on the Internet. Detecting and reducing HS is crucial for the safety and well-being of individuals, as it can otherwise lead to real-world harm and tragedies. Traditional methods of manually monitoring online content are time-consuming, costly, and ineffective in dealing with the vast amount of user-generated content. Therefore, there is a need for automated tools that can efficiently detect and prevent HS, which constitutes the primary goal of this research. In this paper, we describe the methods of data collection that we intend to implement, present a short analysis of the existing solutions, and provide the conceptual solution of the model. -
D.Drašković et al., "Data analysis techniques and detection of propaganda in Serbian online media in 2023"
D.Drašković, M.Ogrizović, M.Dodović, M.Obradović, "Data analysis techniques and detection of propaganda in Serbian online media in 2023", in Applied Artificial Intelligence 4: Medicine, Biology, Chemistry, Financial, Games, Engineering, AAI 2024 - Lecture Notes in Networks and Systems, vol 1446, Springer, Cham, Kragujevac, May 2024 [DOI: https://doi.org/10.1007/978-3-031-99201-8_12]
Link: View paper in Proceedings |
Abstract: Propaganda is a technique by which people manipulate information to direct the behavior of an individual or group, with the aim of provoking a desired reaction. Propaganda is strongly expressed in the spread of religion, political parties, and autocratic governments. In this paper, the most common propaganda techniques are presented, which propaganda implementers can use in shaping and realizing their messages. A certain content of short texts published on the portals of media companies in Serbia was collected. Then, using machine learning techniques, a model was developed, which was trained to classify the text as propaganda or not propaganda. This research included texts that were published on the portals RTS, Politika, B92, Blic, N1, and Danas in 2023. The texts were collected in real-time, because some media portals do not have an archive. -
L.Hrvačević et al., "Development of a web system with an automated question generator based on large language models"
Hrvačević Luka, Cincović Jelica, Milaković Adrian, Jocović Vladimir, Matvejev Valerijan, Drašković Dražen, "Development of a web system with an automated question generator based on large language models," 2024 11th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Niš, Serbia, 2024, pp. 1-6 [DOI: 10.1109/IcETRAN62308.2024.10645106].
Link: View paper in Proceedings |
Abstract: In this paper, we describe the possibility of using large language models (LLMs) in education through the development of a modern web system. A web-based platform employing LLMs to produce questions and answers spanning diverse domains, drawing upon Serbian Wikipedia as its primary knowledge repository. Leveraging LLMs for question-and-answer generation represents a novel methodology in quiz development. Additionally, incorporating Wikipedia enhances the accuracy and pertinence of the generated questions, thereby enriching the overall user experience. -
J. Tufegdžić et al., "Application of WebAssembly technology in high-performance web applications"
Tufegdžić Janko, Dodović Matija, Ogrizović Mihajlo, Babić Nikola, Đukić Jovan, Drašković Dražen, "Application of WebAssembly technology in high-performance web applications," 2024 11th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Niš, Serbia, 2024, pp. 1-6 [DOI: 10.1109/IcETRAN62308.2024.10645198].
Link: View paper in Proceedings |
Abstract: This research paper explores the efficacy of WebAssembly technology in enhancing the performance of web applications, with a focus on graphic-intensive domains such as video games, simulations, and image processing. WebAssembly, a binary instruction format designed for browsers, offers performance comparable to desktop applications by executing code within a secure, low-level virtual machine environment. The study further examines the integration of WebAssembly into various programming languages such as C/C++, C#, and Rust, highlighting its cross-platform capabilities and efficient memory management. Through the development of a website that hosts retro-themed video games, the paper assesses performance across different platforms, demonstrating that while unrestricted desktop platforms show higher speeds, regulated environments exhibit negligible performance discrepancies. The findings suggest that while WebAssembly substantially boosts web application performance, opportunities for further enhancements in areas such as garbage collection, debugging, and JavaScript integration remain. This research underscores WebAssembly's potential to revolutionize web application development, providing a robust framework for future advancements in complex web-based applications. -
M.Ogrizović, D.Drašković, D.Bojić, "Quality assurance strategies for machine learning applications in big data analytics: an overview"
Ogrizović, M., Drašković, D., Bojić, D., "Quality assurance strategies for machine learning applications in big data analytics: an overview," Journal of Big Data 11, 156 (2024) [DOI: https://doi.org/10.1186/s40537-024-01028-y]
Link: View paper |
Abstract: Machine learning (ML) models have gained significant attention in a variety of applications, from computer vision to natural language processing, and are almost always based on big data. There are a growing number of applications and products with built-in machine learning models, and this is the area where software engineering, artificial intelligence and data science meet. The requirement for a system to operate in a real-world environment poses many challenges, such as how to design for wrong predictions the model may make; How to assure safety and security despite possible mistakes; which qualities matter beyond a model’s prediction accuracy; How can we identify and measure important quality requirements, including learning and inference latency, scalability, explainability, fairness, privacy, robustness, and safety. It has become crucial to test thoroughly these models to assess their capabilities and potential errors. Existing software testing methods have been adapted and refined to discover faults in machine learning and deep learning models. This paper covers a taxonomy, a methodologically uniform presentation of all presented solutions to the aforementioned issues, as well as conclusions about possible future development trends. The main contributions of this paper are a classification that closely follows the structure of the ML-pipeline, a precisely defined role of each team member within that pipeline, an overview of trends and challenges in the combination of ML and big data analytics, with uses in the domains of industry and education. -
A.Milaković et al., "Detecting ugly and derogatory words in Serbian language using a web browser extension"
A. Milaković, V. Jocović, J. Cincović, M. Mićović, U. Radenković, D.Drašković, "Detecting ugly and derogatory words in Serbian language using a web browser extension", 2024 32nd Telecommunications Forum (TELFOR), Belgrade, Serbia, November 2024, pp. 1-4 [DOI: https://doi.org/10.1109/TELFOR63250.2024.10819059]
Link: View paper in Proceedings |
Abstract: In natural language processing, data acquisition and preprocessing techniques are significant for experiments involving training models on cleaned data. This paper describes the formation of a dataset of ugly and derogatory words in the Serbian language and the development of a web extension to analyze texts in which such words appear and then their censoring. Developing such an add-on is essential in creating a safer and healthier digital environment for young users who are just developing their Internet habits and adults who want to avoid unwanted content. It is crucial to point out that there are few software tools for natural languages with limited resources, such as the Serbian language. This software could analyze the frequency of certain foul words on different sites, which would contribute to a better understanding of the impact of such language on users. -
D.Drašković et al., "Practical teaching in the field of software engineering"
D.Drašković, T.Šekularac-Obradović, M.Ogrizović, L.Hrvačević, T.Radaljac, D.Bojić, "Practical teaching in the field of software engineering", 20th China - Europe International Symposium on Software Engineering Education (CEISEE 2024), Belgrade, Serbia, 2024. (organised by Harbin Institute of Technology and University of Belgrade) [ISBN: 978-86-85525-34-6]
Link: View Conference Program |
Abstract: Considering the estimates of the growing demand for software engineers in Serbia and the world, the University of Belgrade - School of Electrical Engineering founded a modern study program in Software Engineering in 2004. In this study program, the segment of the program related to classical electrical engineering has been significantly reduced, but specialized courses are taken from the second semester. A perfect side of this study program is the large number of optional subjects, as well as the great attention focused on practical teaching. Students in this study program are expected to complete homeworks starting from the first year, and in the later years of study, they are working on are larger independent or team projects. This paper describes practical teaching in the subjects of the basics of software engineering, such as principles of software engineering, software design, software testing, and software project management. Ways of working with students through homework and project assignments, laboratory exercises, methods of knowledge transfer, scoring systems, and software tools included in the teaching process are highlighted. -
D.Drašković et al., "Visual simulators in the teaching of artificial intelligence"
D.Drašković, A.Milaković, V.Jocović, B.Nikolić, "Visual simulators in the teaching of artificial intelligence", 20th China - Europe International Symposium on Software Engineering Education (CEISEE 2024), Belgrade, Serbia, 2024. (organised by Harbin Institute of Technology and University of Belgrade) [ISBN: 978-86-85525-34-6]
Link: View Conference Program |
Abstract: Teaching machine learning (ML) concepts to students who have no programming experience can be very challenging. In 2021, a visual simulator was introduced in the course Intelligent Systems at the Faculty of Electrical Engineering of the University of Belgrade. This simulator allows students to learn key machine learning concepts without programming, from data selection and preprocessing, hyperparameter selection, and model training. This paper describes the importance of using such simulators in teaching. The paper provides an insight into the results of student success from the previous 6 academic years, which show an increase in student performance through higher passing rates, better grades and a greater number of students achieving the highest grades. This analysis suggests that simulators have an important role in the learning process of complex subjects. -
D.Drašković et al., "Prikupljanje podataka i označavanje u procesu formiranja skupova podataka govora mržnje na srpskom jeziku" (in Serbian; in English: "Data collection and annotation in the process of forming datasets hate speech in the Serbian language")
D.Drašković, U.Radenković, M.Mićović, J.Cincović, A.Milaković, V.Jocović, "Prikupljanje podataka i označavanje u procesu formiranja skupova podataka govora mržnje na srpskom jeziku", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 93-98, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: View Conference Proceedings |
Abstract: Hate speech represents a serious social and technological challenge in the contemporary digital environment, particularly due to its widespread presence on social networks, online forums, and media platforms. The rapid growth of user-generated content, combined with anonymity and the lack of effective moderation, has significantly contributed to the proliferation of discriminatory, offensive, and violent discourse. In this context, the development of high-quality datasets is a crucial prerequisite for building reliable automated systems for hate speech detection, especially for languages with limited digital resources, such as Serbian. This paper presents a comprehensive overview of the data collection and annotation process used in the formation of a hate speech dataset in the Serbian language. The dataset was created within a national research project aimed at preventing textual offenses through artificial intelligence methods. Data were collected from multiple sources, including social networks, online news portals, and public discussion platforms, using both automated techniques (APIs, web crawlers, and scrapers) and manual procedures. The resulting corpus consists of 4,300 short text samples. A three-class annotation scheme was adopted, distinguishing between non-hateful content, offensive language, and hate speech, in accordance with European Union guidelines and relevant legal and ethical frameworks. In addition, hate speech instances were further categorized based on different forms of discrimination, such as national, ethnic, religious, gender-based, and political hatred. The paper also provides statistical and qualitative analyses of the dataset, including class distribution, text length characteristics, and the most frequent terms associated with hate speech. The presented dataset represents a valuable resource for future research in natural language processing and artificial intelligence, enabling the development and evaluation of automated hate speech detection models for the Serbian language. -
A. Mandić et al., "Primena veštačke inteligencije u analizi i obradi govora kroz transkripciju,verifikaciju i evaluaciju izjava" (in Serbian; in English: "Application of artificial intelligence in speech analysis and processing through transcription, verification and evaluation of statements")
Ana Mandić, Marko Jelović, Ana Bulatović, Filip Nikolić, Hana Mijatović, Nikola Vučićević, Ana Stanić, Natalija Bogdanović, Luka Lazović, Anja Mihajlov, Lana Popović, Adrian Milaković, Vladimir Jocović, Dražen Drašković, "Primena veštačke inteligencije u analizi i obradi govora kroz transkripciju,verifikaciju i evaluaciju izjava", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 99-103, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: View Conference Proceedings |
Abstract: In a world where information spreads at an exceptional speed, it is often challenging to distinguish accurate from inaccurate data obtained from the media. Manual analysis of public statements requires a significant amount of time and resources, making it impractical for processing large volumes of information. To address this challenge, a system has been developed that combines the power of large language models with web search, enabling automated fact-checking and the delivery of reliable results. Such technology has a wide range of applications—from media organizations and research teams to anyone seeking trustworthy information and a better understanding of the content presented to them. -
V.Matvejev, D.Drašković, "Predviđanje uspešnosti memorizacije slike pomoću modela mašinskog učenja" (in Serbian; in English: "Predicting Image Memorability Using Machine Learning Models")
V.Matvejev, D.Drašković, "Predviđanje uspešnosti memorizacije slike pomoću modela mašinskog učenja", Zbornik radova 31. IKT konferencije "YU INFO 2025", Informaciono društvo Srbije, pp. 62-65, Kopaonik, Serbia, March 2025 [ISBN: 978-86-85525-33-9]
Link: View Conference Proceedings |
Abstract: Visual attention, i.e., the automatic selection of the most important information within a visual stimulus, is a topic in computer vision that has attracted significant scientific interest. This research focuses on studying the complex relationship between implicit, covert attention and explicit, overt attention, as well as human memory, through a memorability experiment conducted on static images. Thirty images used in the experiment were selected from the FIGRIM image dataset. -
M.Dodović et al., "From Documents to Answers: A University-Focused DBQA System with LLMs"
M.Dodović, J.Tufegdžić, L.Hrvačević, D.Drašković, "Enhancing Sentiment Analysis in Product Reviews: Fine-Tuning BERT for Class Imbalance and Optimal Sequence Representation", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 333-343, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_25]
Link: View Conference Proceedings |
Abstract: This paper presents a document-based question-answering (DBQA) system utilizing a large language model (LLM) to assist students in retrieving relevant information from official university documents. The system effectively processes machine-readable documents by leveraging pre-trained multilingual embeddings and a transformer-based QA model while supporting both Serbian and English queries. The experimental setup focused on extracting relevant context using cosine similarity and answering queries using a fine-tuned QA pipeline, achieving an average accuracy of 84.16%. Evaluation results highlight the system’s strengths in retrieving factual answers while identifying challenges related to answer format variations and partial extractions. This research demonstrates the potential of LLM-based DBQA systems in academic and institutional environments, improving information accessibility for students. -
L.Hrvačević et al., "A Comprehensive Review of Large Language Models for Document-Based Question Answering"
L.Hrvačević, M.Dodović, J.Tufegdžić, D.Drašković, "A Comprehensive Review of Large Language Models for Document-Based Question Answering", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 289-301, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_22]
Link: View Conference Proceedings |
Abstract: This review paper provides a comprehensive survey of Large Language Models (LLMs) applied to Document-Based Question Answering (DBQA). The rapid advancements in LLMs have transformed DBQA systems by enhancing their capabilities in complex reasoning, multi-hop question answering, and contextual understanding. We explore the historical evolution of QA systems before the introduction of LLMs, followed by an in-depth analysis of datasets, benchmarks, and evaluation metrics that underpin DBQA performance. A key contribution of this work is the categorization of LLMs that can perform DBQA based on linguistic focus, distinguishing between monolingual models tailored for specific languages and multilingual models designed to operate across diverse linguistic contexts. Furthermore, we examine notable LLM architectures, their domain-specific adaptations in areas like healthcare and law, and their performance in handling both structured and unstructured data. -
M.Vučinić et al., "Expense tracker using LLM: Mobile application with scanning receipts issued in Serbia"
M.Vučinić, U.Radenković, M.Mićović, V.Jocović, "Expense tracker using LLM: Mobile application with scanning receipts issued in Serbia", Springer's Lecture Notes in Networks and Systems, with title Transformative Technologies Shaping a Smarter Society ICIST 2025, vol. 1621, pp. 517-532, Springer, Cham, Kopaonik, March 2024 [DOI: https://doi.org/10.1007/978-3-032-04890-5_38]
Link: View Conference Proceedings |
Abstract: With the increase in available products and services, unplanned spending has become an indispensable part of everyday life. Planning finances and savings for the future has become a struggle for many. Numerous methods that can be used to track expenses, both modern and traditional, are available. Mobile applications are becoming increasingly popular for tracking and planning personal finances, over traditional approaches like paper and spreadsheets, especially among the younger generation. This paper proposes the implementation of the expense tracking application, providing functionalities that will accelerate input of expenses, such as adding transactions with receipt scanning and automatic categorization. Users can easily add transactions, through an intuitive user interface, by scanning the QR code on the receipt (issued in the Republic of Serbia) or manually. The bill data and items are fetched from the Tax Administration office website. Expenses are automatically categorized and summarized based on bill items using the Large Language Models (LLMs) with minimal user engagement. Classifying costs based on bill items leads to greater precision compared to classifying based on location which is used by most other applications. The charts show the amount of money spent across categories on a monthly and annual level. It is possible to set a limit for each month and observe whether the limit is exceeded over time to achieve more sustainable spending. -
D.Drašković, "Integration of AI tools into an AI-driven software system to make learning programming easier"
D.Drašković, "Integration of AI tools into an AI-driven software system to make learning programming easier", 2025 IEEE Global Engineering Education Conference (EDUCON), London, United Kingdom, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/EDUCON62633.2025.11016313]
Link: View Conference Proceedings |
Abstract: Today, a person can be considered fully digitally literate if they know how to use and integrate ready-made artificial intelligence (AI) tools. The use of AI tools is becoming increasingly common in students' learning processes. However, learning programming can be challenging and exhausting, especially for younger learners. In this research, a software system was developed to integrate multiple AI tools to facilitate the learning process. The system includes tools for speech and text processing, program code generation, code testing, and result verification. Through a user-friendly software interface, users can define a problem or programming task using speech. The software then converts the speech into text using the Whisper AI API, which is subsequently processed by the GPT-3.5 Turbo and Claude AI APIs to generate program code. Once the program code is generated, it undergoes a series of tests, including parallel testing on the LeetCode platform. Users then compare the obtained results and manually complete a survey evaluating both external tools. One key research requirement was for the software system to accept input data in Serbian, a language with limited resources and complex grammatical rules. This made it difficult to find a suitable AI tool for accurate speech-to-text transformation. The system was tested with speech in both English and Serbian but supports many additional languages thanks to the powerful Whisper AI API. The implemented system is modular and easily extensible with new APIs, making it applicable to other areas of education beyond programming. -
V.Milutinović et al., "Applied AI, Teamwork, and Learning in Student Hackathons: Case Study from Serbia"
V.Milutinović, J.Cincović, V.Jocović, D.Drašković, "Applied AI, Teamwork, and Learning in Student Hackathons: Case Study from Serbia", 2025 12th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Cacak, Serbia, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/IcETRAN66854.2025.11114198]
Link: View Conference Proceedings |
Abstract: Student hackathons have emerged as a dynamic educational mechanism for fostering creativity and accelerating the adoption of new technologies among Computer Science and Software Engineering students. First introduced in university settings in the early 2000s, hackathons have evolved into highly engaging events where students compete to develop innovative software or hardware solutions within a limited time frame. The competitive spirit inherent to hackathons resonates strongly with today's engineering students, motivating them to push boundaries, solve real-world problems, and collaborate effectively under pressure. Participation in hackathons enhances students' technical skills, promotes teamwork, and deepens their understanding of modern tools, frameworks, and platforms not always covered in formal curricula. Over the past five years, hackathons have gained remarkable popularity in Serbia, especially at state faculties and through active student organizations. Many of these events are organized in partnership with globally recognized ICT companies, providing students with valuable exposure to industry standards and expectations. At the University of Belgrade, the students' programmers' club, within the Google Developer Group on Campus program, has successfully hosted numerous hackathons that have become key platforms for skill development and innovation. These events not only contribute to academic growth but also significantly enhance students' employability and entrepreneurial thinking. Through hands-on experience and interaction with industry mentors, participants often gain clarity about their professional interests and career paths. Hackathons thus serve as bridges between university education and real-world software engineering practice, preparing students for both modern studies and the tech industry. -
S.Stanković et al., "Comparative Analysis of Machine Learning and Federated Learning in Healthcare"
S.Stanković, P.Vuletić, D.Drašković, "Comparative Analysis of Machine Learning and Federated Learning in Healthcare", 2025 12th International Conference on Electrical, Electronic and Computing Engineering (IcETRAN), Cacak, Serbia, 2025, pp. 1-6 [DOI: https://doi.org/10.1109/IcETRAN66854.2025.11114237]
Link: View Conference Proceedings |
Abstract: With a rapid development of artificial intelligence in healthcare, machine learning and federated learning has emerged as critical technologies for improving decision-making, diagnostics and personalized treatments. This paper presents a comprehensive comparison between traditional machine learning and newer federated approach, focusing on their applications in healthcare. Even though machine learning provides great efficiency in resolving complex tasks in healthcare, it faces great challenges such as data privacy, security and communication cost. In contrast, federated learning offers a decentralized approach which resolves these limitations and allows healthcare institutions to collaboratively train models across multiple devices and locations without sharing sensitive patient data. The experiment conducted in this study utilized a medical dataset to predict whether an individual is an alcohol consumer or not. A range of metrics, including loss, accuracy, precision, recall, AUC, and F1 score, were employed to evaluate and compare the performances of both approaches. By leveraging this technique, federated learning addresses privacy concerns, while maintaining high model performances across distributed dataset. Experiments conducted on healthcare datasets highlight the strengths, challenges and limitations of both machine and federated learning in practical, real-world scenarios. -
D.Bojić, D.Drašković, "Modernizing 90s Era Software to a New Language and Environment Using LLMs - An Empirical Investigation"
D.Bojić, D.Drašković, "Modernizing 90s Era Software to a New Language and Environment Using LLMs - An Empirical Investigation", INTERNATIONAL JOURNAL OF SOFTWARE ENGINEERING AND KNOWLEDGE ENGINEERING, Vol. 35, No. 8, pp. 1099 - 1119, May, 2025 [DOI: https://doi.org/10.1142/S021819402550024X]
Link: View Paper in Journal |
Abstract: Legacy software, particularly from the 1990s, often becomes obsolete due to aging hardware and outdated software environments. Traditionally, software modernization required extensive manual effort, involving reverse engineering, code rewriting, and re-architecting. However, advancements in large language models (LLMs) have introduced new possibilities for automating software translation and modernization. This paper explores the feasibility of using LLMs for modernizing 90s-era Windows applications, specifically migrating legacy C and C++ code to Python. Our methodology includes decompilation, source code analysis, automated translation using ChatGPT, and user interface reconstruction. We empirically evaluate three software projects by analyzing LLM-based translation accuracy across different code structures, including algorithmic logic, file handling, and graphical interfaces. Results indicate that while LLMs achieve high translation accuracy (~88%) for structured code, challenges persist in handling decompiled code and user interface generation. The study provides insights into the effectiveness and limitations of LLMs in real-world software renovation, offering guidelines for leveraging machine learning in legacy system modernization. These findings contribute to both academic research and practical applications, suggesting a pathway for cost-effective and scalable legacy software migration. -
D.Drašković, S.Milanović, "Aspect-based sentiment analysis of user-generated content from a microblogging platform"
Drašković, D., Milanović, S., "Aspect-based sentiment analysis of user-generated content from a microblogging platform," Journal of Big Data 12, 186 (2025) [DOI: https://doi.org/10.1186/s40537-025-01244-0]
Link: View paper |
Abstract: This research presents a practical application of advanced natural language processing techniques to understand people’s feelings during the global Covid-19 pandemic, using a set of big data of over 547 thousand tweets. Companies often use sentiment analysis to process comments, product usage, social media posts, and more, in order to better understand user needs and preferences. In this research paper, aspect-based sentiment analysis is applied as one of the most recent and advanced subtypes of sentiment analysis. Aspect-based sentiment analysis is a modern natural language processing technique that does not perform sentiment detection at the level of the entire input text but individually over all the aspects detected in it. Therefore, this technique enables the precision of analyzing the user data set and making concrete conclusions about people’s feelings. This research aims to develop a software infrastructure for further work in natural language processing using the aspect-based sentiment analysis technique. The proposed process flow and data handling methods, as defined in this research, are designed to be easily adaptable to other data sets with minimal modifications. -
U.Radenković et al., "Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian"
U. Radenković, J. Cincović, A. Milaković, M. Mićović, M. Dodović, V. Jocović, D. Drašković, "Can Large Language Models Replace Human Annotators? A Study on Hate Speech Detection in Serbian," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 409 - 414, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
Abstract: This study focuses on the comparison between human annotation and large language model (LLM)-based annotation of hate speech in Serbian. The dataset consists of short user-generated texts collected from online media portals and social networks. Manual annotation was performed by an expert annotator following detailed labeling guidelines, serving as the reference standard. Automated annotation was conducted using several state-of-the-art LLMs, including GPT-5, Gemini 2.5 Pro, Claude 4, and DeepSeek-R1. The results highlight a strong alignment between human annotation and LLM-based annotation, with GPT-5 achieving the closest agreement with the human annotator. Furthermore, comparative analysis among the top-performing LLMs reveals that, with appropriate fine-tuning, automated annotation can be considered a reliable complement, or in certain contexts, an alternative to manual labeling. -
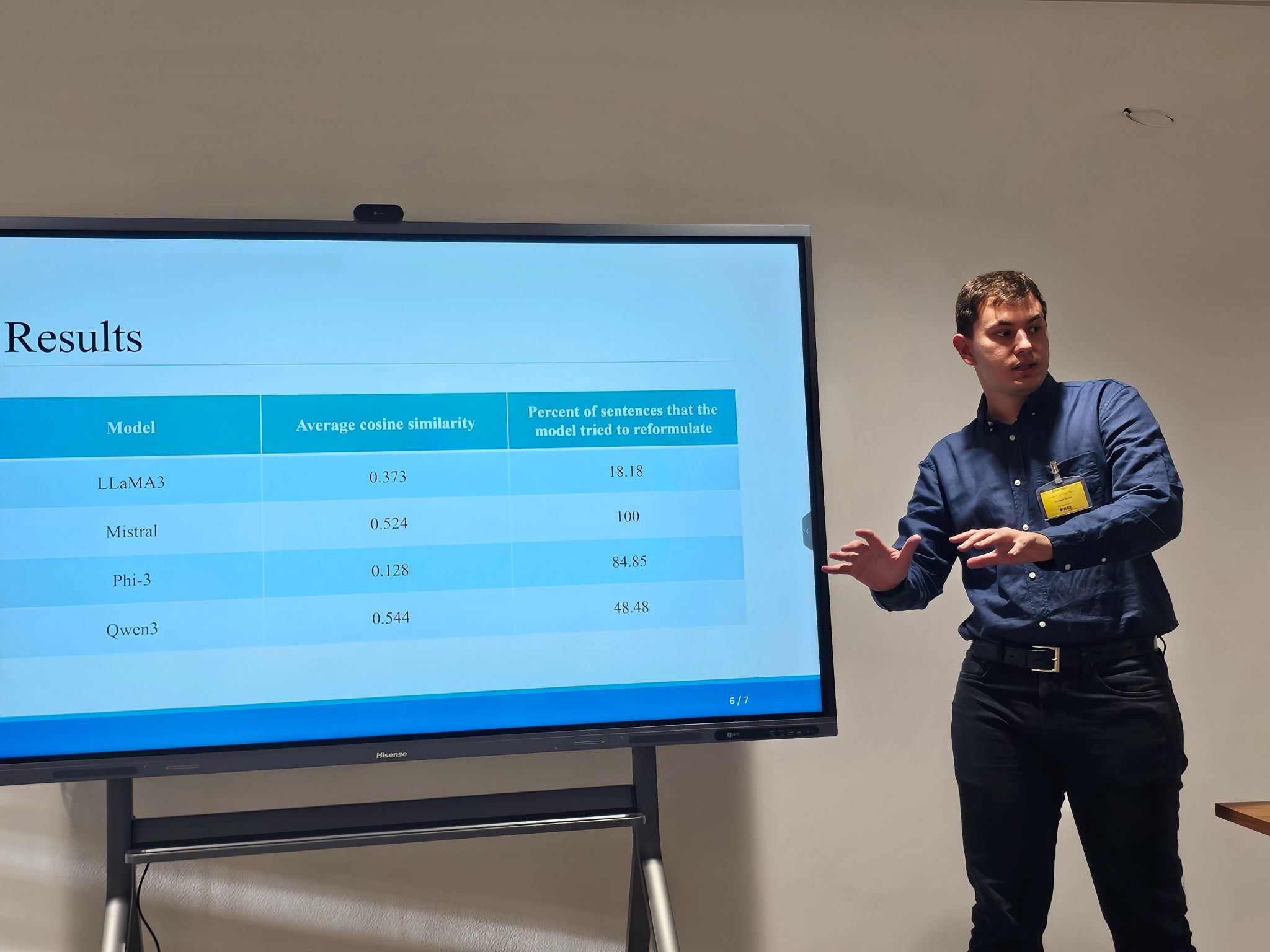
J.Tufegdžić et al., "LLM-Driven Hate Speech Detection in News Content Extracted from URLs"
J. Tufegdžić, L. Hrvačević, M. Dodović, N. Stanković, D. Drašković, "LLM-Driven Hate Speech Detection in News Content Extracted from URLs," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 415 - 420, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
Abstract: This paper presents a system for detecting hate speech in Serbian language in online news articles using large language models (LLMs). While most prior work focuses on social media platforms, news content poses unique challenges due to more subtle, implicit, and editorially framed expressions of hate speech. Our approach integrates a web scraper that extracts clean text from article URLs and a prompt-based LLM classifier that highlights hateful segments without altering the original structure. The research analyzes content in the Serbian language, which is one of the languages with limited resources, but the methodology can be adapted and applied to other languages. To evaluate the system, we tested it on live articles from online Serbian media known for publishing content with hate speech, based on previously annotated datasets from related 2023 studies. We evaluate four state-of-the-art LLMs: LLaMA 3, Mistral, Phi-3, and Qwen3, on a curated dataset of Serbian news articles with human-labeled annotations. Results show that LLaMA 3 most closely aligns with human judgments, while Qwen3 tends to over-tag, and Mistral and Phi-3 often under-tag hate speech. The entire system, including the web interface, is available as open source. Our findings highlight the potential of LLMs for reliable hate speech detection in formal, long-form content and demonstrate the importance of model choice and prompt design for balanced moderation. -
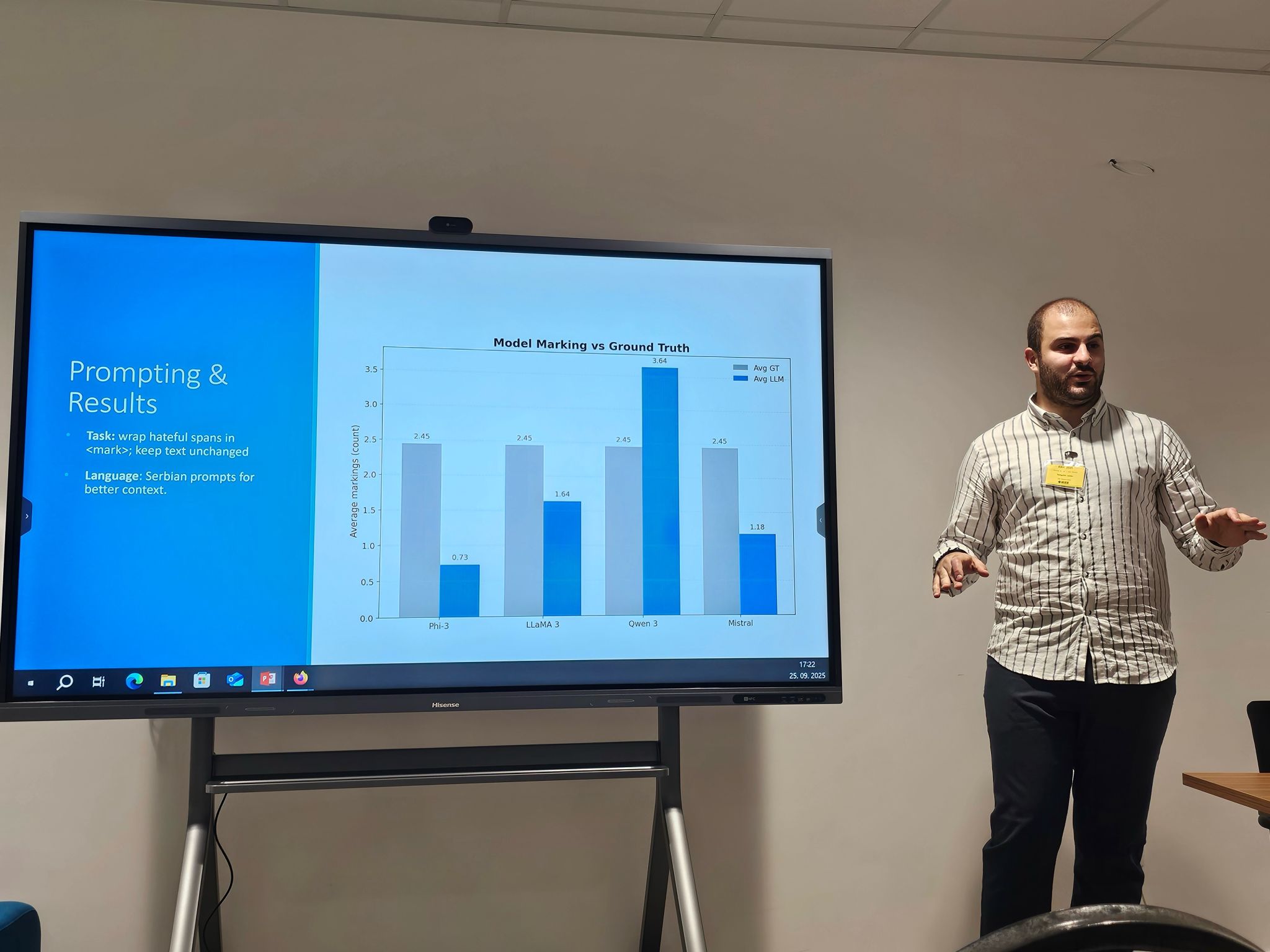
M.Dodović et al., "From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs"
M. Dodović, N. Stanković, J. Tufegdžić, L. Hrvačević, D. Drašković, "From Toxic to Neutral: Automatic Hate Speech Rewriting Using LLMs," Proceedings of the 34th International Electrotechnical and Computer Science Conference ERK 2025, pp. 421 - 426, IEEE Slovenia Section with Faculty of Electrical Engineering University of Ljubljana, Portorož, Slovenia, Sep, 2025 [ISSN/ISBN: 2591-0442 (online)]
Link:
Abstract: This paper presents a system for rewriting hate speech in the Serbian language using large language models (LLMs) to produce culturally appropriate and neutral reformulations. Our approach centers around content purification, which includes removal of hateful, offensive, or discriminatory elements from a sentence while preserving its original intent when possible. The research analyzes content in the Serbian language, which is one of the languages with limited resources, but the methodology can be adapted and applied to other languages as well. The core of the system is a carefully designed prompt, instructing the model to either rewrite the sentence with improved tone or replace it entirely with a neutral message if there is no valuable content. We evaluate four state-of-the-art LLMs: LLaMA 3, Mistral, Phi-3, and Qwen3, using a curated dataset of hate speech examples in Serbian, extracted from comments left on Serbian news articles. The models are run locally using the Ollama framework, ensuring full data privacy and control. Results indicate that Mistral and Qwen3 offer the most consistent and context-aware rewrites, while other models show varying sensitivity to different types of hate speech. Our findings emphasize the effectiveness of prompt-based LLM interaction for hate speech moderation and highlight the importance of prompt design, and model selection in sensitive language-processing tasks. -
V.Matvejev et al., "Web Application for Predicting Image Memorability Using a Machine Learning Model"
V.Matvejev, D.Drašković, B.Nikolić, D.Bojić, "Web Application for Predicting Image Memorability Using a Machine Learning Model", 2025 33rd Telecommunications Forum (TELFOR), Belgrade, Serbia, 2025, pp. 1-4 [DOI: https://doi.org/10.1109/TELFOR67910.2025.11314318]
Link: View paper |
Abstract: Visual attention i.e. the automatic selection of the most important information within a visual stimulus - is a topic within computer vision that attracts considerable scholarly interest. In this study, the focus was on examining the complex relationship between covert (implicit, hidden) and overt (explicit, observable) attention and human memory through a memorability experiment on static images. Thirty images for the experiment were selected from the FIGRIM dataset. The collected eye-tracking data were first used to compute fixation maps and visual saliency maps, and then the IOVC (Inter-Observer Visual Congruency) metric; together with the percentage of successful image memorization (the memorability score), these served as the key parameters of the study. A significant correlation between the IOVC score and the memorability score indicated the possibility of automating the prediction of whether viewing an image would lead to successful memorization based solely on its fixation map. Inspired by this insight, we first trained a machine learning model on the collected viewing data to infer, from a fixation map, which of the 30 images had been viewed. The goal was to train a classifier capable of distinguishing images using only their viewing (eye-tracking) data. The trained model achieved close to 90% accuracy in determining whether an arbitrary fixation map would lead to successful memorization of the given image. A web application that could be used for commercial use for memorability prediction was developed. -
D.Drašković et al., "Using generative AI in hate speech detection for primary and secondary school students"
D.Drašković, J.Cincović, U.Radenković, V.Jocović, M.Mićović, A.Milaković, "Using generative AI in hate speech detection for primary and secondary school students", 2025 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), pp. 1 - 7, IEEE, Macao, Dec, 2025 [DOI: https://ieeexplore.ieee.org/document/11346657]
Link: View paper |
Abstract: Hate speech among children in primary and secondary schools represents a widespread and concerning phenomenon. It is unrealistic to expect young individuals to refrain from discriminatory behavior if they are regularly exposed to hateful rhetoric in their environment. This research focuses on the design and development of a web-based application for the detection and classification of hate speech in the Serbian language, with the broader goal of supporting efforts to reduce hate speech among school-aged children. Serbian, as a South Slavic language with limited natural language processing resources, poses additional challenges for computational analysis compared to globally dominant languages due to the scarcity of publicly available datasets. The implemented software tool leverages generative artificial intelligence, specifically state-of-the-art large language models including GPT-4o, Claude 4, Gemini 2.5-Pro, Llama 3, and DeepSeek-R1. The tool is intended for use in educational contexts in Serbia, providing functionality for the analysis of textual content prior to its publication on internet portals and social media platforms. Key features include the automatic detection of hate speech and the generation of revised, nonhateful versions of the text while preserving its original intent. -
M.Stanojević, D.Drašković, "Razvoj infrastrukture za upravljanje Docker kontejnerima i velikim jezičkim modelima" (in Serbian; in English: "Development of Infrastructure for Managing Docker Containers and Large Language Models")
M.Stanojević, D.Drašković, "Razvoj infrastrukture za upravljanje Docker kontejnerima i velikim jezičkim modelima", Zbornik radova 32. IKT konferencije "YU INFO 2026", Informaciono društvo Srbije, pp. 1-6, Kopaonik, Serbia, March 2026 []
Link: View Conference Proceedings (in publishing!) |
Abstract: With the increasing adoption of large language models across various domains, ranging from natural language processing and intelligent assistants to the automation of complex business processes, there is a growing need for efficient, reliable, and standardized systems that enable their straightforward deployment, maintenance, and scalable management. Large language models require substantial hardware resources, specialized execution environments, and carefully planned mechanisms for task scheduling and comprehensive source code version management, which further underscores the importance of a well-designed infrastructure. At the same time, Docker containers have become one of the key components of modern software architectures. This paper places particular emphasis on system architecture, the organization and automation of processes, as well as the integration of models into complex industrial environments.
Contact Us
Location:
Belgrade 11000, Bulevar kralja Aleksandra 73
Email:
stop@lists.etf.rs